 Skip to content
Skip to content Efficient Data Collection with Hash Tables: ArangoDB Insights
ArangoDB 2.6 will feature an alternative hash implementation of the AQL COLLECT operation. The new implementation can speed up some AQL queries that can not exploit indexes on the COLLECT group criteria.
This blog post provides a preview of the feature and shows some nice performance improvements. It also explains the COLLECT-related optimizer parts and how the optimizer will decide whether to use the new or the traditional implementation.
Document Update with arangoimp: ArangoDB Data Management
Inspired by the feature request in Github issue #1298, we added update and replace support for ArangoDB’s import facilities.
This extends ArangoDB’s HTTP REST API for importing documents plus the arangoimp binary so they can not only insert new documents but also update existing ones.
Inserts and updates can also be mixed in a single import run. What exactly will happen is configurable by setting arangoimp’s new command-line option --on-duplicate.
By default, error will be reported if a document already exists. This behavior can be changed by setting --on-duplicate to a value of update, replace or ignore. Here is an example result of an import with duplicated keys:
> arangoimp --file data.json --collection users --on-duplicate update
created: 1
warnings/errors: 0
updated/replaced: 2
ignored: 0
So, if you want to aggregate data from several data files, you can try the new import command-line option --on-duplicate.
More Efficient Data Exports with new Export API
ArangoDB 2.6 provides a specialized export API for exporting all documents from a collection and shipping them to a client application. It is rather limited but faster than the general-purpose AQL cursor API and can store its snapshots using less memory.

A side effect of the speedup is that the first results will arrive much earlier in the client application. This will help in reducing client connection timeouts in case clients are enforcing them on temporarily non-responding connections. (more…)
Improved Cursor API: ArangoDB Query Efficiency Boost
This week we pushed some modifications for ArangoDB’s cursor API into the devel branch. The change will result in less copying of AQL query results between the AQL and the HTTP layers. As a positive side effect, this will reduce the amount of garbage collection the built-in V8 has to do.
These modifications should improve the cursor API performance significantly for many cases, while at the same time keeping its REST API stable. Client programs do not need to be adjusted to reap the benefits. In a blog post, Jan shows some first unscientific performance tests comparing the old cursor API with its new, improved implementation.
(more…)
Monitoring ArangoDB and individual Foxx Apps with collectd
Great to know your database scales and database vendors like ArangoDB add some statistics on node / cluster health directly in their products.
But running a bunch of different servers and applications you need a central hub to collect monitoring data from all services running. In a series of recipes Willi shows how you could easily add monitoring capabilities to NoSQL databases like ArangoDB using collectd with the cURL JSON plugin. (more…)
Enhanced AQL in ArangoDB 2.5: Improved Query Capabilities
Contained in 2.5 are some small but useful AQL language improvements plus several AQL optimizer improvements.
We are working on further AQL improvements for 2.5, but work is still ongoing. This post summarizes the improvements that are already completed and will be shipped with the initial ArangoDB 2.5 release.
When and how to use sparse indexes in ArangoDB 2.5
This version is deprecated. Download the new version of ArangoDB
In ArangoDB 2.5, hash and skiplist indexes can optionally be made sparse.
Such sparse indexes will exclude documents in which at least one of the index attributes is either not set or has a value of null. Declaring an index as sparse can provide great savings in memory and index creation CPU time for some cases.
ArangoDB Optimizer Rule: Efficient Calculations
In the upcoming ArangoDB 2.5 (current devel branch) a new optimizer rule move-calculations-down was added. Jan showcases in his latest blog post how queries with calculations could benefit from this new optimiser rule.
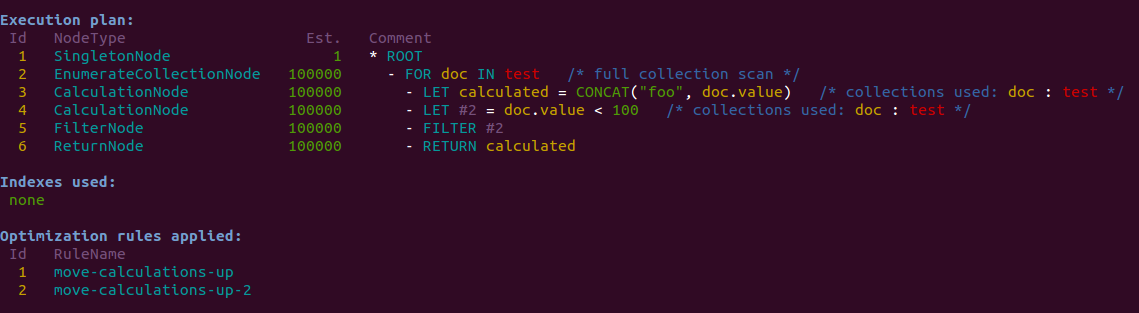
Read in Jan’s blog how this rule could accelerate your queries
Bulk Inserts: MongoDB vs CouchDB vs ArangoDB (Dec 2014)
More than two years ago, we compared the bulk insert performance of ArangoDB, CouchDB and MongoDB in a blog post.
The original blog post dates back to the times of ArangoDB 1.1-alpha. We have been asked several times to re-run the tests with the current versions of the databases. So here we go.
Improved Non-Unique Hash Indexes in ArangoDB 2.3
With ArangoDB 2.3 now getting into the beta stage, it’s time to spread the word about new features and improvements.
Today’s post will be about the changes made to non-unique hash indexes.