 Skip to content
Skip to content Take Alpha 2 of the upcoming ArangoDB 3.7 for a spin!
Estimated reading time: 8 minutes
We are 11 weeks into the development of ArangoDB 3.7 and want to give you yet another opportunity to try out the upcoming features before the release. On our technical preview page, you’ll find the Alpha 2 packages for the Community and Enterprise Edition.
This Alpha 2 comes with pretty neat features and improvements and we hope to get your early feedback!
This is particularly helpful for us to adjust our development in terms of solving real-world problems for you and ease-of-use for the new capabilities like: Read more
Opening the ArangoDB ArangoGraph API & Terraform Provider
Estimated reading time: 0 minutes
ArangoDB ArangoGraph, the cloud service of ArangoDB, has been available for a few months now and is growing quickly. The ArangoGraph team got a lot of requests to provide more ways to manage deployments, access policies and other aspects of ArangoGraph.
After adding support for Azure earlier this year, we’re now opening up the ArangoGraph API for all supported cloud providers like Google Cloud and AWS. Read more
Upcoming ArangoDB 3.7 and Storage Engines
Estimated reading time: 4 minutes
TL;DR
ArangoDB has supported two storage engines for a while: RocksDB and MMFiles. While ArangoDB started out with just the MMFiles storage engine in its early days, RocksDB became the default storage engine in the 3.4 release. Due to its drawbacks ArangoDB 3.6 deprecated the old MMFiles storage engine and with the upcoming 3.7 release we plan to fully remove support. This blog post will provide the background of why storage engines matter, why we chose to deprecate the MMFiles storage engine, and what you should be aware of when migrating from MMFiles to the RocksDB storage engine. Read more
ArangoDB in 10 Minutes with Node.js: Quickstart Guide
Estimated reading time: 10 minutes
This is a short tutorial to get started with ArangoDB using Node.js. In less than 10 minutes you can learn how to use ArangoDB with Node. This tutorial uses a free ArangoDB Sandbox running on ArangoGraph that requires no sign up.
Let’s Get Started!
We will use the Repl live coding environment for the rest of the tutorial. This also requires no sign up and should already be ready to go. Read more
Monitoring ArangoDB with Promotheus and Grafana
Estimated reading time: 5 minutes
Please consider monitoring your productive ArangoDB installation as part of the best practices strategy. It is effortlessly done using established services Prometheus for data collection and Grafana for visualisation and alerting.
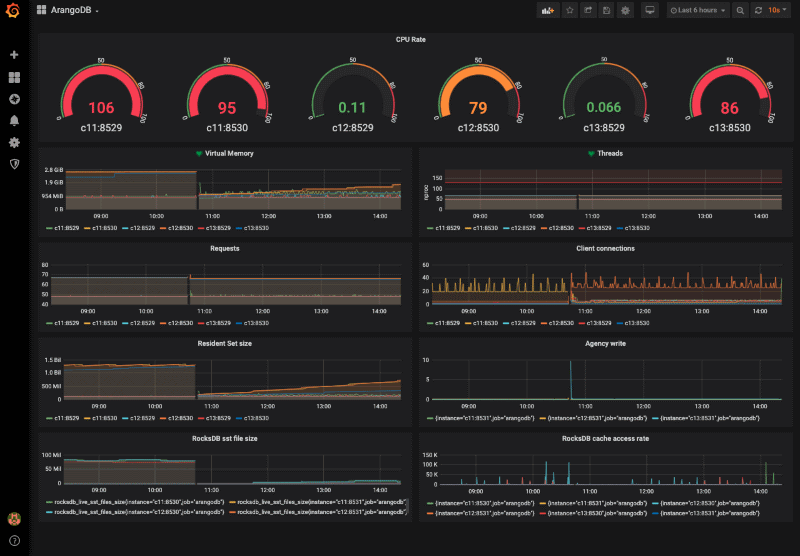
Celebrating Kube-ArangoDB’s 1.0 Release!
Estimated reading time: 4 minutes
Kube-ArangoDB, ArangoDB’s Kubernetes Operator first released two years ago and as of today is operating many ArangoDB production clusters (including ArangoDB’s Managed Service ArangoGraph). With many exciting features we felt kube-arango really deserves to be released as 1.0.
Public Preview of Microsoft Azure Now Available on ArangoDB Oasis
Estimated reading time: 3 minutes
Today we are excited to invite everybody to take the first public preview of Azure on ArangoDB Oasis for a test ride. In case you haven’t joined Oasis yet, please find more details about our offering and a 14-day free trial on cloud.arangodb.com. Just choose Microsoft Azure as your cloud provider and choose from the many regions we already support.
You can share all feedback with us about regions you’d love to see added or other improvements on slack. Please use the #oasis channel on Community Slack or raise an issue via the “Request Help” button in the bottom right corner of Oasis.
Please note that this is a public preview and not meant to be run in production.
Big Thanks to the Microsoft Azure Team
Before we dive into the details of the public preview for Azure on Oasis, we’d like to take a minute to send a big “Thank You!” to the Microsoft Azure team. The responsiveness and quality of their support as well as motivation to help us succeed has been exemplary. When building complex systems everything can’t be perfect but the support of the many different people at Azure has been. Thanks for making it possible to share the Oasis Azure offering so quickly with our community!
Azure on ArangoDB Oasis: That’s in
In this public preview, you can test the full feature set of ArangoDB Oasis on Azure for your projects. We already support a range of Azure regions including
- East US, Virginia: eastus2
- West US, Washington: westus2
- Central Canada, Toronto: canadacentral
- West Europe, Netherlands: westeurope
- UK, London: uksouth
We based the initial regions on customer feedback and can easily add more if you require them. Just use the “Request Help” button in the bottom right corner of Oasis and raise an issue for your preferred region.
Azure Pricing on Oasis
Azure will have a similarly low prices to get started with as ArangoDB Oasis on Google Cloud or AWS. You can get started with as little as $0,27/hour for a 3 node, highly available OneShard setup with 4GB memory and 10GB storage per node.
Please see detailed prices for various setups on the pricing page within Oasis.
Limitations within the Public Preview
Until we can declare Azure on Oasis production-ready, there is still one thing to be fixed. Currently, it is not possible to change the disk size after a deployment has been created. This is something which we want to fix within the next couple of weeks. In case you have an account of type “professional”, you can use a slider to configure the disk size. We also recommend that you only choose well-known values for the disk size.
You can get started with Oasis easily and for free. Just sign-up for Oasis and create your first deployment with just a few clicks. The first 14 days are on the house. No credit card needed. Test-run ends automatically after 14 days of use.
Get started with Oasis on Azure, Google Compute or AWS
Continue Reading
An Introduction to Geo Indexes and their performance characteristics: Part I
ArangoDB 3.3 GA
DC2DC Replication, Encrypted backup, Server-Level Replication and more
Alpha 1 of the upcoming ArangoDB 3.7
Estimated reading time: 6 minutes
We released ArangoDB version 3.6 in January this year, and now we are already 6 weeks into the development of its follow-up version, ArangoDB 3.7. We feel that this is a good point in time to share some of the new features of that upcoming release with you!
We try not to develop new features in a vacuum, but want to solve real-world problems for our end users. To get an idea of how useful the new features are, we would like to make alpha releases available to everyone as soon as possible. Our goal is get early user feedback during the development of ArangoDB, so we can validate our designs and implementations against the reality, and adjust them if it turns out to be necessary.
If you want to give some of the new features a test drive, you can download the 3.7 Alpha 1 from here – Community and Enterprise – for all supported platforms. Read more
Neo4j Fabric: Scaling out is not only distributing data
Estimated reading time: 3 minutes
Neo4j, Inc. is the well-known vendor of the Neo4j Graph Database, which solely supports the property graph model with graphs of previously limited size (single server, replicated).
In early 2020, Neo4j finally released its 4.0 version which promises “unlimited scalability” by the new feature Neo4j Fabric. While the marketing claim of “scalability” is true seen from a very simplistic perspective, developers and their teams should keep a few things in mind – most importantly: True horizontal scalability with graph data is not achieved by just allowing distributing data to different machines. Read more
ArangoML Pipeline Cloud – Managed Machine Learning Metadata Service
Estimated reading time: 4 minutes
We all know how crucial training data for data scientists is to build quality machine learning models. But when productionizing Machine Learning, Metadata is equally important.
Consider for example:
- Capture of Lineage Information (e.g., Which dataset influences which Model?)
- Capture of Audit Information (e.g, A given model was trained two months ago with the following training/validation performance)
- Reproducible Model Training
- Model Serving Policy (e.g., Which model should be deployed in production based on training statistics)
If you would like to see a live demo of ArangoML Pipeline Cloud, join our Head of Engineering and Machine Learning, Jörg Schad, on February 13, 2020 – 10am PT/ 1pm ET/ 7pm CET for a live webinar.
This is the reason we built ArangoML Pipeline, a flexible Metadata store which can be used with your existing ML Pipeline. ArangoML Pipeline can be used as a simple extension of existing ML pipelines through simple python/HTTP APIs.
Check out this page for further details on the challenge of Metadata in Machine Learning and ArangoML Pipeline.
ArangoML Pipeline Cloud
Today we are happy to announce a first version of Managed ML Metadata. Now you can start using ArangoML Pipeline without having to even start a separate docker container.
Additionally, as a cloud-based service based on ArangoDB’s managed cloud service Oasis, it can be up & running in just a few clicks and in the Free-to-Try tier even without a lengthy registration.
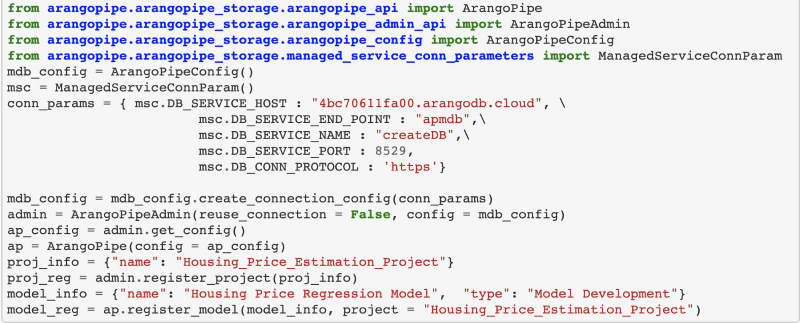
If you already have an existing notebook for your Machine Learning project it is as simple as adding the ArangoML Pipeline configuration pointing to our Free-to-Try tier `arangoml.arangodb.cloud` and a dedicated environment (aka ArangoDB database with custom login credentials) will be generated for you and persisted in the config.
SLAs
ArangoML Pipeline Cloud currently comes with two different service levels:
- Free-to-Try
The Free-to-Try tier allows for a no-hassle setup as it automatically configures your own environment based on a simple API call shown above and is ideas to test ArangoML Pipeline Cloud, but comes with no guarantees for your production data. - Production
If you are considering to use ArangoML Pipeline Cloud for production setup this is- Own Oasis cluster with all of Oasis Enterprise features
- Regular Backup
- It comes with a free 14-day trial period and afterwards follows the Oasis pricing model
Please reach out to arangoml@arangodb.cloud for sign-up and details.
How to get started
To show how easy it is to get started with ArangoML Pipeline Cloud in your existing ML pipeline we have a notebook with a modified TensorFlow Tutorial example with no setup or signup required!
If you are already using ArangoML Pipeline and just want to check how to migrate to ArangoML Pipeline Cloud we suggest to take a look at the minimal minimal example notebook.
While these notebook are mostly focused on the storing of metadata, we have a number of exciting notebooks with use-cases of how to further leverage and analyze metadata including for example datashift analysis.
Learn more:
- Learn more by checking out our example notebook on Google Colab
- Checkout the examples directory in our open source repository.
- Find here a tutorial notebook to get started with ArangoML Pipeline
- Learn more about using Arangopipe with common components of a machine learning stack like Tensorflow, hyperopt and pytorch
- Learn more about ArangoML Pipeline: Visit the blog
- To join a webinar for a live demo of how ArangoML Pipeline Cloud works: Register here
Continue Reading
InfoCamere investigated graph databases and chose ArangoDB
Performance analysis with pyArango: Part III Measuring possible capacity with usage Scenarios
Milestone 2 ArangoDB 3.3 – New Data Replication Engine and Hot Standby