 Skip to content
Skip to content 
Neo4j Fabric: Scaling out is not only distributing data
Estimated reading time: 3 minutes
Neo4j, Inc. is the well-known vendor of the Neo4j Graph Database, which solely supports the property graph model with graphs of previously limited size (single server, replicated).
In early 2020, Neo4j finally released its 4.0 version which promises “unlimited scalability” by the new feature Neo4j Fabric. While the marketing claim of “scalability” is true seen from a very simplistic perspective, developers and their teams should keep a few things in mind – most importantly: True horizontal scalability with graph data is not achieved by just allowing distributing data to different machines.
We refer to actual horizontal scalability of a graph database if you have the option to
- scale out with highly interconnected data
- use the same query everywhere without caring about actual sharding
- add more database nodes any time / redistribute data across database nodes
- evenly distribute data and work to prevent storage and performance hotspots
ArangoDB is capable of supporting all of these requirements, as it is designed as a scalable, distributed multi-model database, using a hybrid-index approach for graph database capabilities and fast traversal lookups.
In addition, nodes and edges are being stored as full JSON-documents, allowing ArangoDB to support a high degree of flexibility in data modeling (incl. nested properties).
Comparison Overview:
| ArangoDB | Neo4j 4.0 Fabric | |
| Administration | Centralized Cluster Administration. | All shards are individual clusters which have to be administered and kept in sync manually. |
| Sharding Schema | One schema. | Manual definition of sharding schema for each individual sub-graph and database. |
| Data Loading and Sharding | One loading job and automatic sharding by configurable sharding key. | User manually partitions data, loads data separately to each database. |
| Querying (read) | Query as a single database. Same query everywhere. | The user needs to build multi-stage queries to manually query each sub-graph and then merge the results. |
| Querying (write) | Query as a single database. Same query everywhere. | The user needs to build multi-stage queries, manually synchronize proxy nodes and shared data. |
Summed up: Neo4j Fabric is a federation of separate databases. With ArangoDB you have a natively distributed database which supports distributed query processing, automatic sharding as well as a simple setup & deployment. Users can achieve high end performance of graphy queries running against distributed data by using the SmartGraph feature.
The SmartGraph feature in ArangoDB, introduced in 2016, allows executing queries in a highly efficient manner against distributed data. Fine-tuned ever since, customers run sharded graphs in production for years.
SmartGraphs allows for automatic sharding along with a user defined sharding key. In addition, ArangoDB’s query engine automatically detects where the data needed for a given query resides. ArangoDB then automatically distributes the execution to the query engines on each DB Server for local query processing. Only the intermediate results are sent from the DB Servers to the coordinator which compiles the final set of results. This approach together with a smart sharding algorithm reduces network latency during query processing to the absolute minimum.
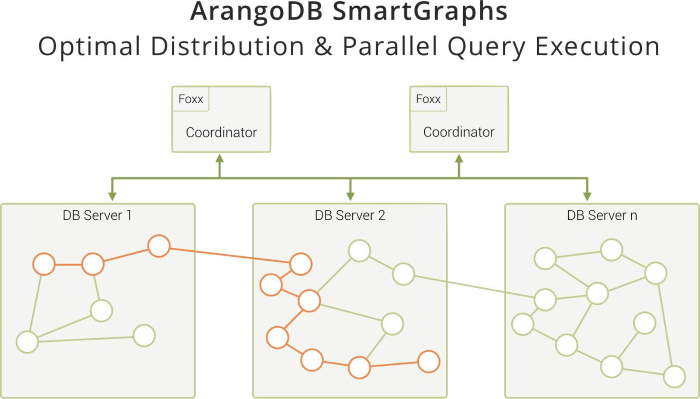
Read more about ArangoDB SmartGraphs on our feature page or get a more fine-grained introduction to the challenges and solutions of scaling with highly interconnected data from our Head of Graph Development on Youtube.
Feel free to contact us directly for any questions about SmartGraphs and scaling with graph databases.
Continue Reading
RocksDB smoothing for ArangoDB customers
Get the latest tutorials, blog posts and news: