 Skip to content
Skip to content ArangoDB 3.5 Released: Distributed Joins & Transactions
We are super excited to share the latest upgrades to ArangoDB which are now available with ArangoDB 3.5. With the fast-growing team, we could build many new and long-awaited features in the open-source edition and Enterprise Edition. Get ArangoDB 3.5 on our download page and see all changes in the Changelog.
Need to know more about multi-model?
Maybe good to know: Our Cloud Service offering, ArangoDB ArangoGraph, will run the full Enterprise Edition of ArangoDB 3.5 including all security as well as special features. You can find more about ArangoDB ArangoGraph and play around for 14-days free in the cloud.
Join the upcoming ArangoDB 3.5 Feature Overview Webinar to have a detailed walkthrough on the release with our Head of Engineering and Machine Learning, Jörg Schad.
tl;dr Highlights of ArangoDB 3.5
- SmartJoins which enable you to run efficient co-located JOIN operations against distributed data (Enterprise Edition)
- The long awaited Streaming Transactions API which lets you run & manage ACID transactions directly from your driver (Java Sync, Go, JavaScript & PHP already supported)
- ArangoSearch improvements including configurable analyzers, lightning fast sorted indexes and other goodies
- Extended graph database capabilities like k-shortest path and the new PRUNE keyword
- Data Masking lets you work securely with obfuscated production data for real-world development & testing environments (Enhanced Data Masking available in Enterprise)
- Helpful updates like Time-To-Live Indexes, Index Hints and Named Indexes
- And a little late to the party… Lightning fast consistent Cluster Backups (following with 3.5.1/ Enterprise-only)
Keen to learn more? Let’s take a closer look at the new features.
SmartJoins - Co-located JOINs in a NoSQL Database
There are many operational and analytical use cases where sharding two large collections is needed, and fast JOIN operations between these collections is an important requirement.
In close teamwork with some of our largest customers, we developed SmartJoins (available in ArangoDB Enterprise only). This new feature allows to shard large collections to a cluster in a way that keeps data to be joined on the same machines. This smart sharding technique allows co-located JOIN operation in ArangoDB many might know from RDBMS but now available in a multi-model NoSQL database.
While our first offering of distributed JOIN operations, SatelliteCollections, allows for sharding one large collection and replicating many smaller ones for local joining, SmartJoins allow two large collections to be sharded to an ArangoDB cluster, with JOIN operations executed locally on the DBservers. This minimizes network latency during query execution and provides the performance close to a single instance for analytical and operational workloads.
For example, let’s assume we have two large collections, e.g. `Products` and `Orders`, which have a one-to-many relationship as each product can appear in any order. You can now use e.g. the `productId` during the creation of the collection to shard the two collections alike (see arangosh example below):
db._create("products", { numberOfShards: 3, shardKeys: ["_key"] });
db._create("orders", { distributeShardsLike: "products", shardKeys: ["productId"] });When querying both collections with your normal join query in AQL, the query engine will automatically recognize that you sharded the data in a SmartJoin-fashion and only send the query to the relevant DB-servers for local query execution. Network overhead is thereby reduced to an absolute minimum.
For more details you can either check out the SmartJoins tutorial or watch the walk through below showing off some first performance indications and how to even combine SmartJoins with SatelliteCollections:
Streaming Transactions API - Execute & Control ACID Transactions From Your Language Driver
ArangoDB supported ACID transactions basically from the very beginning, either via AQL operations or by writing transactions in JavaScript. The new streaming transactions API now allows users to BEGIN, COMMIT or ABORT (rollback) operations from all supported drivers (i.e., Java Sync, GO, JavaScript, PHP).
With the streaming transaction API, a transaction can consist of a series of transactional operations and therefore allows clients to construct larger transactions in a much more efficient way than the previous JavaScript-based solution. You can also leverage various configurations for your transactions to meet your individual needs, like:
- Collections: The collections the transaction will need for any write operation
- waitForSync: An optional boolean flag to force the transaction to write to disk before returning
- allowImplicit: Allows the transaction to read from undeclared collections
- lockTimeout: Lets you specify the maximum time for the transaction to be completed (default is 10 minutes)
- maxTransactionSize: If you are using RocksDB as your storage engine (default engine since ArangoDB 3.4), you can define the maximal size of your transaction in bytes
For more details, please see the documentation for Streaming Transactions. If you are maintaining an ArangoDB driver, please see the RC blogpost for details around integrating the new API into your driver.
Please note: Streaming transactions come with full ACID guarantees on a single instance and provide also a better transactional experience in a cluster setting. ArangoDB does not support distributed ACID transactions -- yet.
Search Engine Upgrades - Configurable Analyzers and Lightning-Fast Sorted Queries
Frankly, we are absolutely thrilled about how many people embrace ArangoSearch and build amazing applications with it. Having a fully integrated C++ based search & ranking engine within a multi-model database seems to come in very handy for many people out there. New to ArangoSearch? Check out the tutorial
We enlarged the ArangoSearch team and can now release two huge improvements to the search capabilities of ArangoDB: Configurable Analyzers & Super Fast Sorted Queries.
Configurable Analyzers let you perform case-sensitive searches, word stemming and also let you use your own language-specific stopword lists. They also let you fine-tune your ArangoSearch queries even better for a broad variety of languages, including English, French, German, Chinese and many more. Check out the tutorial on how to work with Configurable Analyzers in ArangoDB.
Queries including sorting will see a real performance boost in ArangoDB 3.5 when using the new sorted indexes. When creating a `view` for ArangoSearch you can now specify the creation of this new index and define which sort order is best for your queries (asc/dec). If the sort order in your query matches the one specified in your view, results can be directly read from the index and returned super fast. Internal benchmarks show a performance improvement of up to 1500x for these situations.
Creating a sorted view can be done via `arangosh`
db._createView('myView', 'arangosearch', { links : { ... }, primarySort: [ { field: 'myField', direction: 'asc' }, { field: 'anotherField', direction: 'desc' } ] })
db._query('FOR d in myView SEARCH ... SORT d.myField ASC RETURN d`); // no sorting at query time
For more details on Sorted Views & ArangoSearch, check out the video tutorial below:
Additional Upgrades to ArangoSearch
Besides the new key features of ArangoSearch, you can now access and also use the relevance scores calculated by the BM25 or TFIDF algorithms directly in queries to e.g. limit searches to only include results meeting a minimum relevancy to your query.
Restricting search queries to specific collections can provide performance benefits for your queries. If your ArangoSearch `view` spans multiple collections, you can now limit your search queries to specific collections which you can define within your search queries. This can provide a significant performance boost, as less data has to be accessed.
For more details, please see the blog post for ArangoSearch Updates.
Graph Database Upgrades - k-shortest path and new PRUNE keyword
As one of the leading graph databases out there, ArangoDB already provides a rich feature set ranging from simple graph traversals to complex distributed graph processing.
New to graphs?
The new k-shortest path feature adds to this featureset and provides the option to query for all shortest paths between two given vertices, returning sorted results based on path length or path weight. Imagine you transferred a transportation network to a graph dataset and now navigate between two given points. With k-shortest path, you can query for shortest travel distance, shortest travel time, least amount of road fees or any other information you have stored on edges.
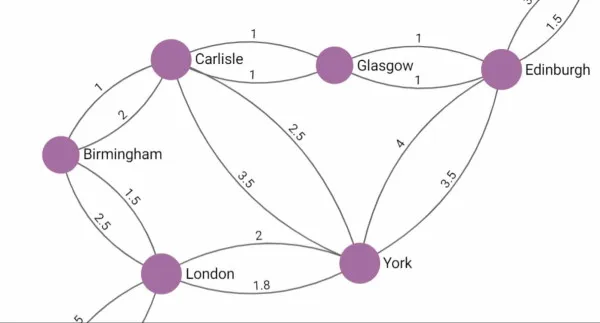
In the example of the European railroad connections above, we could e.g. query for the shortest distance, least stops or cheapest fare for traveling between London and Glasgow depending on the information you have stored at your edges. You can also think of various network management use cases or threat intelligence for applying the new k-shortest path feature.
If you’d like to dive a bit deeper into k-shortest paths, you can watch the video tutorial or get hands-on with the tutorial in our training center.
The new PRUNE keyword is an alternative for FILTERs in AQL graph traversal queries. Using PRUNE allows users to reduce the amount of documents the traversal query has to look up. PRUNE acts like a stop condition within graph traversals, telling the traversal to stop when a given criteria is met and return the full result path.
In contrast to pure FILTER queries, which first lookup all potential results and then apply the filter condition on all results found, PRUNE directly applies the filter condition directly to each vertex. Queries using PRUNE can, therefore, reduce the amount of total lookups needed and speed up queries significantly. By using PRUNE, internal tests show a performance gain by several orders of magnitude in some use cases. See one of these cases yourself in the video tutorial below:
Data Masking – For GDPR and CCPA-compliant Testing & Development
Testing new versions of a production environment or developing new features is best when you do so as close to production as possible. But, exporting sensitive data like names, birthdays, email addresses or credit card information from highly-secure production systems to be used in lower-security testing and development environments is often not possible -- or poses GDPR / CCPA compliance issues. Data Masking to the rescue!
The new Data Masking feature in ArangoDB lets you define sensible data to be obfuscated, then generates masked exports of these collections to be used for testing or development purposes.
The open-source edition of ArangoDB supports already a simple version of Data Masking, letting you obfuscate arbitrary data with random strings which can already be quite helpful.
But the Enterprise Edition of ArangoDB takes things a few steps further and lets you preserve the structure of the data while obfuscating it. Birthdays, credit card numbers, email addresses or other sensitive data can be defined and obfuscated in a way that preserves the structure for testing experiences as close to production as possible. Try Data Masking yourself with this tutorial.
Hot Backups – Little late to the Party (coming with 3.5.1)
Creating consistent snapshots across a distributed environment is a challenging problem.
With hot backups in the Enterprise Edition, you can create automatic, consistent backups of your ArangoDB cluster without noticeable impact on your production systems. In contrast to Arangodump, hot backups are taken on the level of the underlying storage engine and hence both backup and restore are considerably faster.
Hot backups will be available in the Enterprise Edition. Stay tuned for more details.
Neat and helpful upgrades
In addition to the new features outlined above, ArangoDB 3.5 also includes smaller improvements that add to a nice and easier experience with ArangoDB.
Sort-Limit Optimization in AQL is for specific use cases to speed up queries where it is not possible to use an index to sort the results. You can check out the tutorial with performance gain indications on our blog.
Time-to-Live Indexes allow you to automatically remove documents after a certain period of time or at a specific date. This can be useful for e.g. automatically removing session data or also with GDPR rules like “The right to be forgotten”. Check out the TTL tutorial for more details.
Index Hints allow users to provide the query optimizer with a hint that a certain index should be used. The query optimizer will then take a closer look at the index hinted. Users can also enforce the usage of a specific index. Find more details in this brief tutorial.
When using many indexes within a collection it can come in handy to name them. With Named Indexes users can now specify a name for an index to make navigating through indexes much easier. Learn how to use named indexes in this tutorial.
Of course, there are dozens of other optimizations under the hood, including performance tuning, cluster improvements and much more. Take ArangoDB 3.5 for a test drive and see for yourself. Any feedback is, as always, highly appreciated! If you are upgrading from a previous version, check our General Upgrade Guide.
Did these new features get you excited and you are curious whats next for ArangoDB? Join the “ArangoDB 3.6: The Future is Full of Features” webinar with our Head of Engineering & Machine Learning Joerg Schad.
We hope you find many useful new features and improvements in ArangoDB 3.5. If you like to join the ArangoDB Community, you can do so on GitHub, Stack Overflow and Slack.
ArangoDB 3.4 GA
Full-text Search, GeoJSON, Streaming & More
The ability to see your data from various perspectives is the idea of a multi-model database. Having the freedom to combine these perspectives into a single query is the idea behind native multi-model in ArangoDB. Extending this freedom is the main thought behind the release of ArangoDB 3.4.
We’re always excited to put a new version of ArangoDB out there, but this time it’s something special. This new release includes two huge features: a C++ based full-text search and ranking engine called ArangoSearch; and largely extended capabilities for geospatial queries by integrating Google™ S2 Geometry Library and GeoJSON. Read more
ArangoDB 3.3: DC2DC Replication, Encrypted Backup
Just in time for the holidays we have a nice present for you all - ArangoDB 3.3. This release focuses on replication, resilience, stability and thus on general readiness for your production small and very large use cases. There are improvements for the community as well as for the Enterprise Edition. We sincerely hope to have found the right balance between them.
In the Community Edition there are:
- Easier server-level replication
- A resilient active/passive mode for single server instances with automatic failover
- RocksDB throttling for increased guaranteed write performance
- Faster collection and shard creation in the cluster
- Lots of bug fixes (most of them have been backported to 3.2)
In the Enterprise Edition there are:
- Datacenter to datacenter replication for clusters
- Encrypted backup and restore
That is, this is all about improving replication and resilience. For us, the two new exciting features are datacenter to datacenter replication and the resilient active-passive mode for single-servers.
Datacenter to datacenter replication
Every company needs a disaster recovery plan for all important systems. This is true from small units like single processes running in some container to the largest distributed architectures. For databases in particular this usually involves a mixture of fault-tolerance, redundancy, regular backups and emergency plans. The larger a data store, the more difficult it is to come up with a good strategy.
Therefore, it is desirable to be able to run a distributed database in one datacenter and replicate all transactions to another datacenter in some way. Often, transaction logs are shipped over the network to replicate everything in another, identical system in the other datacenter. Some distributed data stores have built-in support for multiple datacenter awareness and can replicate between datacenters in a fully automatic fashion.
ArangoDB 3.3 takes an evolutionary step forward by introducing multi-datacenter support, which is asynchronous datacenter to datacenter replication. Our solution is asynchronous and scales to arbitrary cluster sizes, provided your network link between the datacenters has enough bandwidth. It is fault-tolerant without a single point of failure and includes a lot of metrics for monitoring in a production scenario.
Read more on the Datacenter to Datacenter Replication and follow generic installation instructions.
This is a feature available only in the Enterprise Edition.
Server-level replication
We have had asynchronous replication functionality in ArangoDB since release 1.4. But setting it up was admittedly too hard. One major design flaw in the existing asynchronous replication was that the replication is for a single database only.
Replicating from a leader server that has multiple databases required manual fiddling on the follower for each individual database to replicate. When a new database was created on the leader, one needed to take action on the follower to ensure that data for that database got actually replicated. Replication on the follower also was not aware of when a database was dropped on the leader.
This is now fixed in 3.3. In order to set up replication on a 3.3 follower for all databases of a given 3.3 leader, there is now the so-called `globalApplier`. It has the same interface as the existing `applier`, but it will replicate from all database on the leader and not just a single one.
As a consequence, server-global replication can now be set up permanently with a single JavaScript command or API call.
A resilient active/passive mode for single server instances with automatic failover
While it was always possible to set up two servers and connect them via asynchronous replication, the replication setup was not straightforward (see above), and it also did not handle automatic failover. In case of the leader having died, one needed to have some machinery in place to stop replication on the follower and make it the leader. ArangoDB did not provide this machinery, and left it to client applications to solve the failover problem.
With 3.3, this has become much easier. There is now a mode to start two arangod instances as a pair of connected servers with automatic failover.
The two servers are connected via asynchronous replication. One of the servers is the elected leader, and the other one is made a follower automatically. At startup, the two
servers race for leadership. The follower will automatically start replication from the leader for all databases, using the server-global replication (see above).
When the leader goes down, this is automatically detected by an agency instance, which
is also started in this mode. This instance will make the previous follower stop its replication and make it the new leader.
The follower will automatically deny all read and write requests from client applications. Only the replication is allowed to access the follower's data until the follower becomes a new leader.
The arangodb starter does support starting two servers with asynchronous replication and failover out of the box, making the setup even easier.
The arangojs driver for JavaScript, GO, PHP Java drivers for ArangoDB are also in the making to support automatic failover in case the currently used server endpoint responds with HTTP 503. Read more details on the Java driver.
Encrypted backup
This feature allows to create an encrypted backup using arangodump. We use AES256 for the encryption. The encryption key can be read from a file or from a generator program. It works in single server and cluster mode. Together with the encryption at rest this allows to keep all your sensible data encrypted whenever it is not in memory.
Here is an example for encrypted backup:
arangodump --collection "secret" dump --encryption.keyfile ~/SECRET-KEYAs you can see, in order to create an encrypted backup, simply add the --encryption.keyfile option when invoking arangodump. Needless to say, restore is equally easy using arangorestore.
The key must be exactly 32 bytes long (this is a requirement of the AES block cipher we are using). For details see the documentation in the manual.
Note that encrypted backups can be used together with the already existing RocksDB encryption-at-rest feature, but they can also be used for the MMFiles engine, which does not have encryption-at-rest.
This is a feature available only in the Enterprise Edition.
RocksDB throttling
While throttling may sound bad at first, the RocksDB throttling is there for a good reason. It throttles write operations to RocksDB in the RocksDB storage engine, in order to prevent total stalls. The throttling is adaptive, meaning that it automatically adapts to the write rate. Read more about RocksDB throttling.
Faster shard creation in cluster
Creating collections is what all ArangoDB users do. It's one of the first steps carried out. So it should be as quick as possible.
When using the cluster, users normally want resilience, so replicationFactor is set to at least 2. The number of shards is often set to pretty high values (collections with 100 shards).
Internally this will first store the collection metadata in the agency, and then the assigned shard leaders will pick up the change and will begin creating the shards. When the shards are set up on the leader, the replication is kicked off, so every data modification will not only become effective on the leader, but also on the followers. This process has got some shortcuts for the initial creation of shards in 3.3.
Conclusion
The entire ArangoDB team is proud to release version 3.3 of ArangoDB just in time for the holidays! We hope you will enjoy the upgrade. We invite you to take ArangoDB 3.3 for a spin and to let us know what you think via our Community Slack channel or hacker@arangodb.com. We look forward to your feedback!
AWS Neptune: A New Vertex in the Graph World — But Where’s the Edge?
At AWS Re:Invent just a few days ago, Andy Jassy, the CEO of AWS, unveiled their newest database product offerings: AWS Neptune. It’s a fully managed, graph database which is capable of storing RDF and property graphs. It allows developers access to data via SPARQL or java-based TinkerPop Gremlin. As versatile and as good as this may sound, one has to wonder if another graph database will solve a key problem in modern application development and give Amazon an edge over its competition. Read More
ArangoDB 3.3 Beta Release – New Features and Enhancements
It is all about improving replication. ArangoDB 3.3 comes with two new exciting features: data-center to data-center replication for clusters and a much improved active-passive mode for single-servers. ArangoDB 3.3 focuses on replications and improvements in this area and provides a much better user-experience when setting up a resilient single-servers with automatic failover.
This beta release is feature complete and contains stability improvements with regards to the recent milestone 1 and 2 of ArangoDB 3.3. However, it is not meant for production use, yet. We will provide ArangoDB 3.3 GA after extensive internal and external testing of this beta release. Read More
Setting up Datacenter to Datacenter Replication in ArangoDB
Please note that this tutorial is valid for the ArangoDB 3.3 milestone 1 version of DC to DC replication!
Interested in trying out ArangoDB? Fire up your cluster in just a few clicks with ArangoDB ArangoGraph: the Cloud Service for ArangoDB. Start your free 14-day trial here
This milestone release contains data-center to data-center replication as an enterprise feature. This is a preview of the upcoming 3.3 release and is not considered production-ready.
In order to prepare for a major disaster, you can setup a backup data center that will take over operations if the primary data center goes down. For a server failure, the resilience features of ArangoDB can be used. Data center to data center is used to handle the failure of a complete data center.
Data is transported between data-centers using a message queue. The current implementation uses Apache Kafka as message queue. Apache Kafka is a commonly used open source message queue which is capable of handling multiple data-centers. However, the ArangoDB replication is not tied to Apache Kafka. We plan to support different message queues systems in the future.
The following contains a high-level description how to setup data-center to data-center replication. Detailed instructions for specific operating systems will follow shortly. Read more
Auto-Generate GraphQL for ArangoDB
Currently, querying ArangoDB with GraphQL requires building a GraphQL.js schema. This is tedious and the resulting JavaScript schema file can be long and bulky. Here we will demonstrate a short proof of concept that reduces the user related part to only defining the GraphQL IDL file and simple AQL queries.
The Apollo GraphQL project built a library that takes a GraphQL IDL and resolver functions to build a GraphQL.js schema. Resolve functions are called by GraphQL to get the actual data from the database. I modified the library in the way that before the resolvers are added, I read the IDL AST and create resolver functions.
To simplify things and to not depend on special "magic", let's introduce the directive `@aql`. With this directive, it's possible to write an AQL query that gets the needed data. With the bind parameter `@current` it is possible to access the current parent object to do JOINs or related operations.
Interested in trying out ArangoDB? Fire up your database in just a few clicks with ArangoDB ArangoGraph: the Cloud Service for ArangoDB. Start your free 14-day trial here.
A GraphQL IDL
type BlogEntry {
_key: String!
authorKey: String!
author: Author @aql(exec: "FOR author IN Author FILTER author._key == @current.authorKey RETURN author")
}
type Author {
_key: String!
name: String
}
type Query {
blogEntry(_key: String!): BlogEntry
}This IDL describes a `BlogEntry` and an `Author` object. The `BlogEntry` holds an `Author` object which is fetched via the AQL query in the directive `@aql`. The type Query defines a query that fetches one `BlogEntry`.
Now let's have a look at a GraphQL query:
{
blogEntry(_key: "1") {
_key
authorKey
author {
name
}
}
}This query fetches the `BlogEntry` with `_key` "1". The generated AQL query is:
FOR doc IN BlogEntry FILTER doc._key == '1' RETURN docAnd with the fetched `BlogEntry` document the corresponding `Author` is fetched via the AQL query defined in the directive.
The result will approximately look like this:
{
"data" : {
"blogEntry" : {
"_key" : "1",
"authorKey" : "2",
"author" : {
"name" : "Author Name"
}
}
}
}As a conclusion of this short demo, we can claim that with the usage of GraphQLs IDL, it is possible to reduce effort on the users' side to query ArangoDB with GraphQL. For simple GraphQL queries and IDLs it's possible to automatically generate resolvers to fetch the necessary data.
The effort resulted in an npm package is called graphql-aql-generator.
ArangoDB Foxx example
Now let’s have a look at the same example, but with using ArangoDB javascript framework - Foxx. To do so, we have to follow the simple steps listed below:
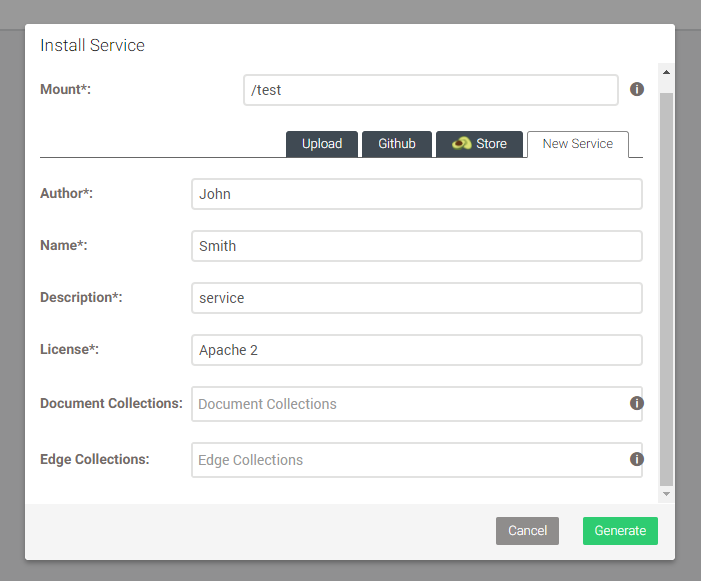
- Open the ArangoDB web interface and navigate to `SERVICES`.
- Then click `Add Service`. Select `New Service` and fill out all fields with `*`.
Important is the `Mount` field. I will use `/test`. Then Generate. - Click on the service to open its settings. Click `Settings` and then go to `Set Development` to enable the development mode.
- Then click `Info` and open the path at `Path:`.
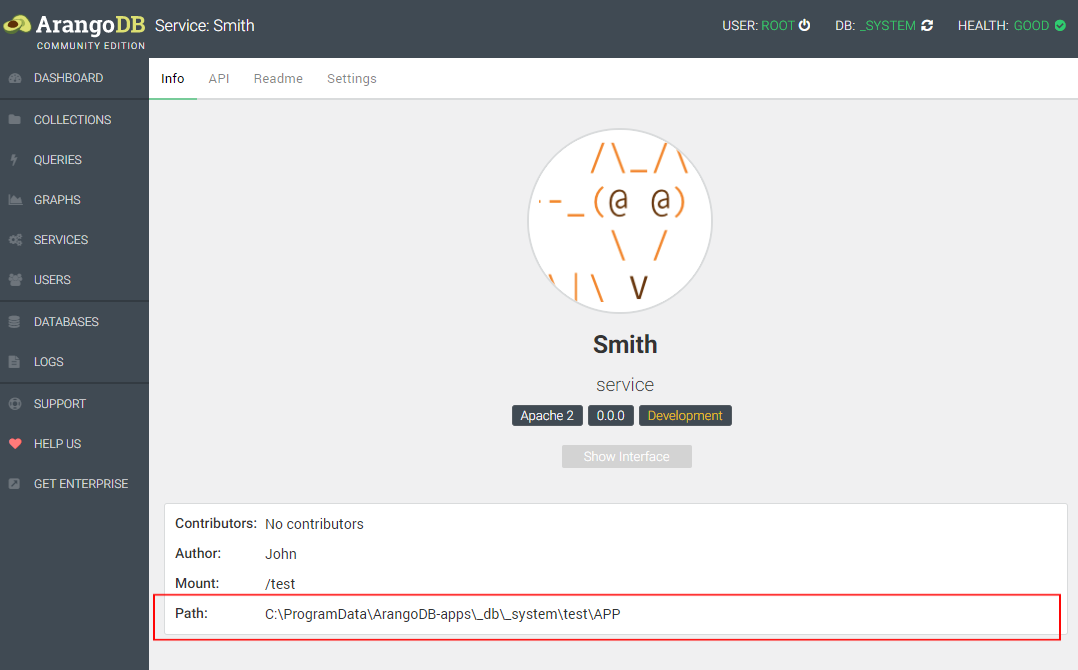
Now we have to install the npm package:
npm install --save graphql-aql-generatorWe also need the collections `Author` and `BlogEntry`. And the following documents:
- `Author` collection:
{
"_key":"2"
"name": "Author Name"
}- `BlogEntry` collection:
{
"_key":"1"
"authorKey": "2"
}Foxx has a built-in graphql router that we can use to serve GraphQL queries. We assemble a new route called `/graphql` that serves the incoming GraphQL queries. With `graphiql: true` we enable the GraphiQL explorer so we can test-drive our queries.
const createGraphQLRouter = require('@arangodb/foxx/graphql');
const generator = require('graphql-aql-generator');
const typeDefs = [`...`]
const schema = generator(typeDefs);
router.use('/graphql', createGraphQLRouter({
schema: schema,
graphiql: true,
graphql: require('graphql-sync')
}));Open `127.0.0.1:8529/test/graphql` and the GraphiQL explorer is loaded so we can execute a query to fetch a `BlogEntry` with an `Author`.
{
blogEntry(_key: "1") {
_key
authorKey
author {
name
}
}
}
```
The result is:
```
{
"data": {
"blogEntry": {
"_key": "1",
"authorKey": "2",
"author": {
"name": "Author Name"
}
}
}
}For the sake of completeness, here is the full Foxx example that works by copy & paste. Do not forget to
`npm install graphql-aql-generator` and create the collections and documents.
// main.js code
'use strict';
const createRouter = require('@arangodb/foxx/router');
const router = createRouter();
module.context.use(router);
const createGraphQLRouter = require('@arangodb/foxx/graphql');
const generator = require('graphql-aql-generator');
const typeDefs = [`
type BlogEntry {
_key: String!
authorKey: String!
author: Author @aql(exec: "FOR author in Author filter author._key == @current.authorKey return author")
}
type Author {
_key: String!
name: String
}
type Query {
blogEntry(_key: String!): BlogEntry
}
`]
const schema = generator(typeDefs);
router.use('/graphql', createGraphQLRouter({
schema: schema,
graphiql: true,
graphql: require('graphql-sync')
}));Would be great to hear your thoughts, feedback, questions, and comments in our Slack Community channel or via a contact us form.
ArangoDB | Pronto Move Shard – Multi-Model NoSQL Database
In July Adobe announced that they plan the End-of-Life for flash at around 2020.
As HTML5 progressed and due to a long history of critical security vulnerabilities this is – technologically speaking – certainly the right decision. However I tended to also become a bit sad.
Flash was the first technology that brought interactivity to the web. We tend to forget how static the web was in the early 2000s. Flash brought life to the web and there were plenty of stupid trash games and animations which I really enjoyed at the time. As a homage to the age of trashy flash games I created a game which resembles the games of this era: Read more
ArangoDB 3.2: RocksDB, Pregel, Fault Tolerant Foxx, Satellite Collections
We are pleased to announce the release of ArangoDB 3.2. Get it here. After an unusually long hackathon, we eliminated two large roadblocks, added a long overdue feature and integrated an interesting new one into this release. Furthermore, we’re proud to report that we increased performance of ArangoDB on average by 35%, while at the same time reduced the memory footprint compared to version 3.1. In combination with a greatly improved cluster management, we think ArangoDB 3.2 is by far our best work. (see release notes for more details)
One key goal of ArangoDB has always been to provide a rock solid platform for building ideas. Our users should always feel safe to try new things with minimal effort by relying on ArangoDB. Todays 3.2 release is an important milestone towards this goal. We’re excited to release such an outstanding product today.
RocksDB
![]() With the integration of Facebook's RocksDB, as a first pluggable storage engine in our architecture, users can now work with as much data as fits on disk. Together with the better locking behavior of RocksDB (i.e., document-level locks), write intensive applications will see significant performance improvements. With no memory limit and only document-level locks, we have eliminated two roadblocks for many users. If one chooses RocksDB as the storage engine, everything, including indexes will persist on disk. This will significantly reduce start-up time.
With the integration of Facebook's RocksDB, as a first pluggable storage engine in our architecture, users can now work with as much data as fits on disk. Together with the better locking behavior of RocksDB (i.e., document-level locks), write intensive applications will see significant performance improvements. With no memory limit and only document-level locks, we have eliminated two roadblocks for many users. If one chooses RocksDB as the storage engine, everything, including indexes will persist on disk. This will significantly reduce start-up time.
See this how-to on “Comparing new RocksDB and mmfiles engine” to test the new engine for your operating system and use case.
Pregel
Distributed graph processing was a missing feature in ArangoDB’s graph toolbox. We’re willing to admit that, especially since we managed to fill this need by implementing the Pregel computing model.
With PageRank, Community Detection, Vertex Centrality Measures and further algorithms, ArangoDB can now be used to gain high-level insights into the hidden characteristics of graphs. For instance, you can use graph processing capabilities to detect communities. You can then use the results to shard your data efficiently to a cluster and thereby enable SmartGraph usage to its full potential. We’re confident that with the integration of distributed graph processing, users will now have one of the most complete graph toolsets available in a single database.
Test the new pregel integration with this Community Detection Tutorial and further sharpen advanced graph skills with this new tutorial about Using SmartGraphs in ArangoDB.
Fault-Tolerant Foxx Services
Many people already enjoy using our Foxx JavaScript framework for data-centric microservices. Defining your own highly configurable HTTP routes with full access to the ArangoDB core on the C++ level can be pretty handy. In version 3.2, our Foxx team completely rewrote the management internals to support fault-tolerant Foxx services. This ensures multi-coordinator clusters will always keep their services in sync, and new coordinators are fully initialized, even when all existing coordinators are unavailable.
Test the new fault-tolerant Foxx yourself or learn Foxx by following the brand new Foxx tutorial.
Powerful Graph Visualization
Managing and processing graph data may not be enough, causing visualizing insights to be important. No worries. With ArangoDB 3.2, this can be handled easily. You can use the open-source option via arangoexport to export the data and then import it into Cytoscape (check out the tutorial).

Or you can just plug in the brand new Keylines 3.5 via Foxx and install an on-demand connection. With this option, you will always have the latest data visualized neatly in Keylines without any export/import hassle. Just follow this tutorial to get started with ArangoDB and Keylines.

Read-Only Users
To enhance basic user management in ArangoDB, we added Read-Only Users. The rights of these users can be defined on database and collection levels. On the database level, users can be given administrator rights, read access or denied access. On the collection level, within a database, users can be given read/write, read only or denied access. If a user is not given access to a database or a collection, the databases and collections won’t be shown to that user. Take the tutorial about new User Management.
We also improved geo queries since this is becoming more important to our community. With geo_cursor, it’s now possible to sort documents by distance to a certain point in space (Take the tutorial). This makes queries simple like, “Where can I eat vegan in a radius of one mile around Times Square?” We plan to add support for other geo-spatial functions (e.g., polygons, multi-polygons) in the next minor release. So watch for that.
ArangoDB 3.2 Enterprise Edition: More Room for Secure Growth
The Enterprise Edition of ArangoDB is focused on solving enterprise-scale problems and secure work with data. In version 3.1, we introduced SmartGraphs to bring fast traversal response times to sharded datasets in a cluster. We also added auditing and enhanced encryption control. Download ArangoDB Enterprise Edition (forever free evaluation).
Working closely with one of our larger clients, we further explored and improved an idea we had about a year ago. Satellite Collections is the exciting result of this collaboration. It’s designed to enable faster join operations when working with sharded datasets. To avoid expensive network hops during join processing among machines, one has ‘only’ to find a solution to enable joins locally.
With Satellite Collections, you can define collections to shard to a cluster, as well as set collections to replicate to each machine. The ArangoDB query optimizer knows where each shard is located and sends requests to the DBServers involved, which then execute the query locally. The DBservers will then send the partial results back to the Coordinator which puts together the final result. With this approach, network hops during join operations on sharded collections can be avoided, hence query performance is increased and network traffic reduced. This can be more easily understood with an example. In the schema below, collection C is sharded to multiple machines, while the smaller satellites (i.e., S1 - S5) are replicated to each machine, orbiting the shards of C.

Use cases for Satellite Collection are plentiful. In this more in-depth blog post, we use the example of an IoT case. Personalized patient treatment based on genome sequencing analytics is another excellent example where efficient join operations involving large datasets, can help improve patient care and save infrastructure costs.
Security Enhancements
From the very beginning of ArangoDB, we have been concerned with security. AQL is already protected from injections. By using Foxx, sensitive data can be contained within in a database, with only the results being passed to other systems, thus minimizing security exposure. But this is not always enough to meet enterprise scale-security requirements. With version 3.1, we introduced Auditing and Enhanced Encryption Control and with ArangoDB 3.2, we added even more protection to safeguard data.
Encryption at Rest
With RocksDB, you can encrypt the data stored on disk using a highly secure AES algorithm. Even if someone steals one of your disks, they won’t be able to access the data. With this upgrade, ArangoDB takes another big step towards HIPAA compliance.
Enhanced Authentication with LDAP
Normally, users are defined and managed in ArangoDB itself. With LDAP, you can use an external server to manage your users. We have implemented a common schema which can be extended. If you have special requirements that don’t fit into this schema, please let us know.
Conclusion & You
The entire ArangoDB team is proud to release version 3.2 of ArangoDB -- this should not be a surprise considering all of the improvements we made. We hope you will enjoy the upgrade. We invite you to take ArangoDB 3.2 for a spin and to let us know what you think. We look forward to your feedback!
Download ArangoDB 3.2
Database Security Reminder: Protect Your Data
With billions of objects and people connected to the internet and your precious data sometimes exposed publicly security is one of the most important topics to discuss. In light of recent ransomware attacks, databases exposed and other breaches we’d like to share a quick reminder on how to secure your ArangoDB environment.
Attacks can be prevented with the security protections built into the product. We strive to prevent possible security issues by giving appropriate reminders in our web console when authentication is disabled:
