 Skip to content
Skip to content 
ArangoDB 3.5 Released: Distributed Joins & Transactions
We are super excited to share the latest upgrades to ArangoDB which are now available with ArangoDB 3.5. With the fast-growing team, we could build many new and long-awaited features in the open-source edition and Enterprise Edition. Get ArangoDB 3.5 on our download page and see all changes in the Changelog.
Need to know more about multi-model?
Maybe good to know: Our Cloud Service offering, ArangoDB ArangoGraph, will run the full Enterprise Edition of ArangoDB 3.5 including all security as well as special features. You can find more about ArangoDB ArangoGraph and play around for 14-days free in the cloud.
Join the upcoming ArangoDB 3.5 Feature Overview Webinar to have a detailed walkthrough on the release with our Head of Engineering and Machine Learning, Jörg Schad.
tl;dr Highlights of ArangoDB 3.5
- SmartJoins which enable you to run efficient co-located JOIN operations against distributed data (Enterprise Edition)
- The long awaited Streaming Transactions API which lets you run & manage ACID transactions directly from your driver (Java Sync, Go, JavaScript & PHP already supported)
- ArangoSearch improvements including configurable analyzers, lightning fast sorted indexes and other goodies
- Extended graph database capabilities like k-shortest path and the new PRUNE keyword
- Data Masking lets you work securely with obfuscated production data for real-world development & testing environments (Enhanced Data Masking available in Enterprise)
- Helpful updates like Time-To-Live Indexes, Index Hints and Named Indexes
- And a little late to the party… Lightning fast consistent Cluster Backups (following with 3.5.1/ Enterprise-only)
Keen to learn more? Let’s take a closer look at the new features.
SmartJoins - Co-located JOINs in a NoSQL Database
There are many operational and analytical use cases where sharding two large collections is needed, and fast JOIN operations between these collections is an important requirement.
In close teamwork with some of our largest customers, we developed SmartJoins (available in ArangoDB Enterprise only). This new feature allows to shard large collections to a cluster in a way that keeps data to be joined on the same machines. This smart sharding technique allows co-located JOIN operation in ArangoDB many might know from RDBMS but now available in a multi-model NoSQL database.
While our first offering of distributed JOIN operations, SatelliteCollections, allows for sharding one large collection and replicating many smaller ones for local joining, SmartJoins allow two large collections to be sharded to an ArangoDB cluster, with JOIN operations executed locally on the DBservers. This minimizes network latency during query execution and provides the performance close to a single instance for analytical and operational workloads.
For example, let’s assume we have two large collections, e.g. `Products` and `Orders`, which have a one-to-many relationship as each product can appear in any order. You can now use e.g. the `productId` during the creation of the collection to shard the two collections alike (see arangosh example below):
db._create("products", { numberOfShards: 3, shardKeys: ["_key"] });
db._create("orders", { distributeShardsLike: "products", shardKeys: ["productId"] });When querying both collections with your normal join query in AQL, the query engine will automatically recognize that you sharded the data in a SmartJoin-fashion and only send the query to the relevant DB-servers for local query execution. Network overhead is thereby reduced to an absolute minimum.
For more details you can either check out the SmartJoins tutorial or watch the walk through below showing off some first performance indications and how to even combine SmartJoins with SatelliteCollections:
Streaming Transactions API - Execute & Control ACID Transactions From Your Language Driver
ArangoDB supported ACID transactions basically from the very beginning, either via AQL operations or by writing transactions in JavaScript. The new streaming transactions API now allows users to BEGIN, COMMIT or ABORT (rollback) operations from all supported drivers (i.e., Java Sync, GO, JavaScript, PHP).
With the streaming transaction API, a transaction can consist of a series of transactional operations and therefore allows clients to construct larger transactions in a much more efficient way than the previous JavaScript-based solution. You can also leverage various configurations for your transactions to meet your individual needs, like:
- Collections: The collections the transaction will need for any write operation
- waitForSync: An optional boolean flag to force the transaction to write to disk before returning
- allowImplicit: Allows the transaction to read from undeclared collections
- lockTimeout: Lets you specify the maximum time for the transaction to be completed (default is 10 minutes)
- maxTransactionSize: If you are using RocksDB as your storage engine (default engine since ArangoDB 3.4), you can define the maximal size of your transaction in bytes
For more details, please see the documentation for Streaming Transactions. If you are maintaining an ArangoDB driver, please see the RC blogpost for details around integrating the new API into your driver.
Please note: Streaming transactions come with full ACID guarantees on a single instance and provide also a better transactional experience in a cluster setting. ArangoDB does not support distributed ACID transactions -- yet.
Search Engine Upgrades - Configurable Analyzers and Lightning-Fast Sorted Queries
Frankly, we are absolutely thrilled about how many people embrace ArangoSearch and build amazing applications with it. Having a fully integrated C++ based search & ranking engine within a multi-model database seems to come in very handy for many people out there. New to ArangoSearch? Check out the tutorial
We enlarged the ArangoSearch team and can now release two huge improvements to the search capabilities of ArangoDB: Configurable Analyzers & Super Fast Sorted Queries.
Configurable Analyzers let you perform case-sensitive searches, word stemming and also let you use your own language-specific stopword lists. They also let you fine-tune your ArangoSearch queries even better for a broad variety of languages, including English, French, German, Chinese and many more. Check out the tutorial on how to work with Configurable Analyzers in ArangoDB.
Queries including sorting will see a real performance boost in ArangoDB 3.5 when using the new sorted indexes. When creating a `view` for ArangoSearch you can now specify the creation of this new index and define which sort order is best for your queries (asc/dec). If the sort order in your query matches the one specified in your view, results can be directly read from the index and returned super fast. Internal benchmarks show a performance improvement of up to 1500x for these situations.
Creating a sorted view can be done via `arangosh`
db._createView('myView', 'arangosearch', { links : { ... }, primarySort: [ { field: 'myField', direction: 'asc' }, { field: 'anotherField', direction: 'desc' } ] })
db._query('FOR d in myView SEARCH ... SORT d.myField ASC RETURN d`); // no sorting at query time
For more details on Sorted Views & ArangoSearch, check out the video tutorial below:
Additional Upgrades to ArangoSearch
Besides the new key features of ArangoSearch, you can now access and also use the relevance scores calculated by the BM25 or TFIDF algorithms directly in queries to e.g. limit searches to only include results meeting a minimum relevancy to your query.
Restricting search queries to specific collections can provide performance benefits for your queries. If your ArangoSearch `view` spans multiple collections, you can now limit your search queries to specific collections which you can define within your search queries. This can provide a significant performance boost, as less data has to be accessed.
For more details, please see the blog post for ArangoSearch Updates.
Graph Database Upgrades - k-shortest path and new PRUNE keyword
As one of the leading graph databases out there, ArangoDB already provides a rich feature set ranging from simple graph traversals to complex distributed graph processing.
New to graphs?
The new k-shortest path feature adds to this featureset and provides the option to query for all shortest paths between two given vertices, returning sorted results based on path length or path weight. Imagine you transferred a transportation network to a graph dataset and now navigate between two given points. With k-shortest path, you can query for shortest travel distance, shortest travel time, least amount of road fees or any other information you have stored on edges.
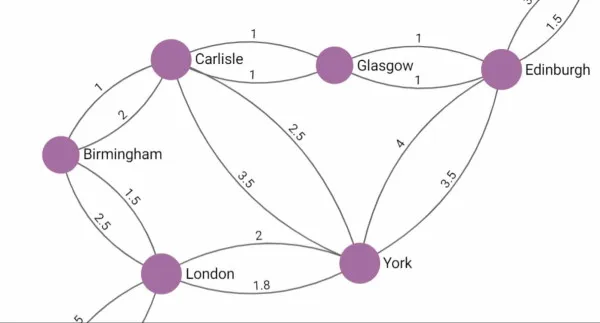
In the example of the European railroad connections above, we could e.g. query for the shortest distance, least stops or cheapest fare for traveling between London and Glasgow depending on the information you have stored at your edges. You can also think of various network management use cases or threat intelligence for applying the new k-shortest path feature.
If you’d like to dive a bit deeper into k-shortest paths, you can watch the video tutorial or get hands-on with the tutorial in our training center.
The new PRUNE keyword is an alternative for FILTERs in AQL graph traversal queries. Using PRUNE allows users to reduce the amount of documents the traversal query has to look up. PRUNE acts like a stop condition within graph traversals, telling the traversal to stop when a given criteria is met and return the full result path.
In contrast to pure FILTER queries, which first lookup all potential results and then apply the filter condition on all results found, PRUNE directly applies the filter condition directly to each vertex. Queries using PRUNE can, therefore, reduce the amount of total lookups needed and speed up queries significantly. By using PRUNE, internal tests show a performance gain by several orders of magnitude in some use cases. See one of these cases yourself in the video tutorial below:
Data Masking – For GDPR and CCPA-compliant Testing & Development
Testing new versions of a production environment or developing new features is best when you do so as close to production as possible. But, exporting sensitive data like names, birthdays, email addresses or credit card information from highly-secure production systems to be used in lower-security testing and development environments is often not possible -- or poses GDPR / CCPA compliance issues. Data Masking to the rescue!
The new Data Masking feature in ArangoDB lets you define sensible data to be obfuscated, then generates masked exports of these collections to be used for testing or development purposes.
The open-source edition of ArangoDB supports already a simple version of Data Masking, letting you obfuscate arbitrary data with random strings which can already be quite helpful.
But the Enterprise Edition of ArangoDB takes things a few steps further and lets you preserve the structure of the data while obfuscating it. Birthdays, credit card numbers, email addresses or other sensitive data can be defined and obfuscated in a way that preserves the structure for testing experiences as close to production as possible. Try Data Masking yourself with this tutorial.
Hot Backups – Little late to the Party (coming with 3.5.1)
Creating consistent snapshots across a distributed environment is a challenging problem.
With hot backups in the Enterprise Edition, you can create automatic, consistent backups of your ArangoDB cluster without noticeable impact on your production systems. In contrast to Arangodump, hot backups are taken on the level of the underlying storage engine and hence both backup and restore are considerably faster.
Hot backups will be available in the Enterprise Edition. Stay tuned for more details.
Neat and helpful upgrades
In addition to the new features outlined above, ArangoDB 3.5 also includes smaller improvements that add to a nice and easier experience with ArangoDB.
Sort-Limit Optimization in AQL is for specific use cases to speed up queries where it is not possible to use an index to sort the results. You can check out the tutorial with performance gain indications on our blog.
Time-to-Live Indexes allow you to automatically remove documents after a certain period of time or at a specific date. This can be useful for e.g. automatically removing session data or also with GDPR rules like “The right to be forgotten”. Check out the TTL tutorial for more details.
Index Hints allow users to provide the query optimizer with a hint that a certain index should be used. The query optimizer will then take a closer look at the index hinted. Users can also enforce the usage of a specific index. Find more details in this brief tutorial.
When using many indexes within a collection it can come in handy to name them. With Named Indexes users can now specify a name for an index to make navigating through indexes much easier. Learn how to use named indexes in this tutorial.
Of course, there are dozens of other optimizations under the hood, including performance tuning, cluster improvements and much more. Take ArangoDB 3.5 for a test drive and see for yourself. Any feedback is, as always, highly appreciated! If you are upgrading from a previous version, check our General Upgrade Guide.
Did these new features get you excited and you are curious whats next for ArangoDB? Join the “ArangoDB 3.6: The Future is Full of Features” webinar with our Head of Engineering & Machine Learning Joerg Schad.
We hope you find many useful new features and improvements in ArangoDB 3.5. If you like to join the ArangoDB Community, you can do so on GitHub, Stack Overflow and Slack.
Get the latest tutorials, blog posts and news: