 Skip to content
Skip to content 
ArangoDB 3.4 GA
Full-text Search, GeoJSON, Streaming & More
The ability to see your data from various perspectives is the idea of a multi-model database. Having the freedom to combine these perspectives into a single query is the idea behind native multi-model in ArangoDB. Extending this freedom is the main thought behind the release of ArangoDB 3.4.
We’re always excited to put a new version of ArangoDB out there, but this time it’s something special. This new release includes two huge features: a C++ based full-text search and ranking engine called ArangoSearch; and largely extended capabilities for geospatial queries by integrating Google™ S2 Geometry Library and GeoJSON.
ArangoDB 3.4 also includes performance improvements on many fronts. Just one example is the improved performance and scalability for multi-core machines. Our tests show up to 100% faster query execution for multi-core machines.
Together with the over forty additional improvements, we think that ArangoDB 3.4 is another important landmark on the projects’ mission to make the following ideas as easy as possible.
Interested in trying out ArangoDB? Fire up your cluster in just a few clicks with ArangoDB ArangoGraph: the Cloud Service for ArangoDB. Start your free 14-day trial here
Let’s look at some of the new features.
ArangoSearch
A Full-text Search & Similarity Ranking Engine
ArangoSearch is a C++ based search and ranking engine fully integrated into ArangoDB as a first-class citizen. ArangoSearch allows you to combine search with any other supported access pattern in ArangoDB.
Search uses a special type of materialized view to provide full-text search across multiple collections at once. Within the definition of a view type arangosearch, you specify entire collections or individual fields to be covered by an inverted index with one or more general text analyzers. The view concept is currently exclusive to ArangoSearch, more general views (SQL like views, materialized views) may be introduced with later versions of ArangoDB.
ArangoSearch – The View Concept:
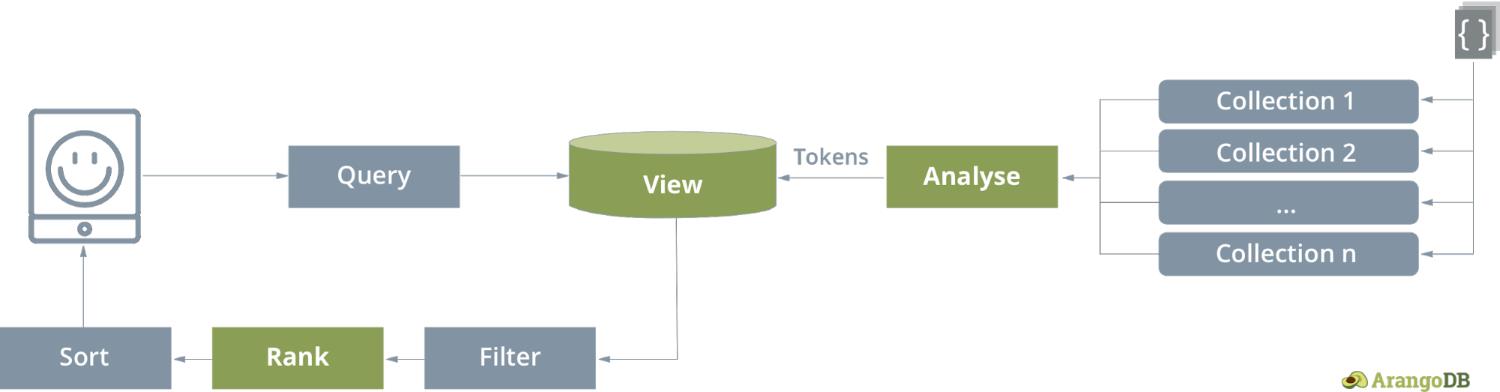
The capabilities in this first release include the following:
- Relevance-Based Matching
- Phrase and Prefix Matching
- Complex Searches with Boolean Operators
- Relevance Tuning on Runtime
- Full combinability of search queries with all supported data models & access patterns
ArangoSearch is not only a search, but also a similarity ranking engine. We have integrated two ranking algorithms (i.e., BM25 and TFIDF) which will allow you to rank the overall results or boost certain query parameters to fine-tune the relevance of search results. In addition, this first version of ArangoSearch already includes twelve language-specific analyzers including English, Chinese, German, Spanish, Finnish, Dutch and many more.
Combining ArangoSearch, for example, with ArangoDB’s graph database capabilities fits nicely with enhanced fraud detection, knowledge graphs, semantic search, and even precision medicine use cases leveraging genomic data.
ArangoSearch is cluster-ready and can be used for datasets exceeding one machine. In a cluster setting, the Coordinator is always responsible for query planning, optimization and execution, guiding incoming queries to the right DBserver to process queries locally. With this architecture, efficient search queries can be performed against data residing on different machines.

We hope you will find that ArangoSearch is a useful extension of the ArangoDB capabilities and are excited to hear what you create with it.
Learn the new search capabilities with the ArangoSearch tutorial or deepen your knowledge about the underlying architecture of ArangoSearch.
Full GeoJSON support & Google S2 Index

Another important feature we want to highlight is much improved support for location-based applications. Simple geo queries like points and distances have been possible and efficient with ArangoDB for a long time. But with ArangoDB 3.4 and the new GeoJSON support, you can now build sophisticated applications requiring precise and fast geo queries.
The new GeoJSON support includes all geo primitives like multi-points, multi-polygons and many geo functions like GEO_DISTANCE, GEO_CONTAINS, GEO_EQUALS — even GEO_INTERSECTS. Of course, you can combine the new geospatial capabilities with all supported data models and also within ArangoSearch-based queries.
Go through the GeoJSON tutorial to try it out.
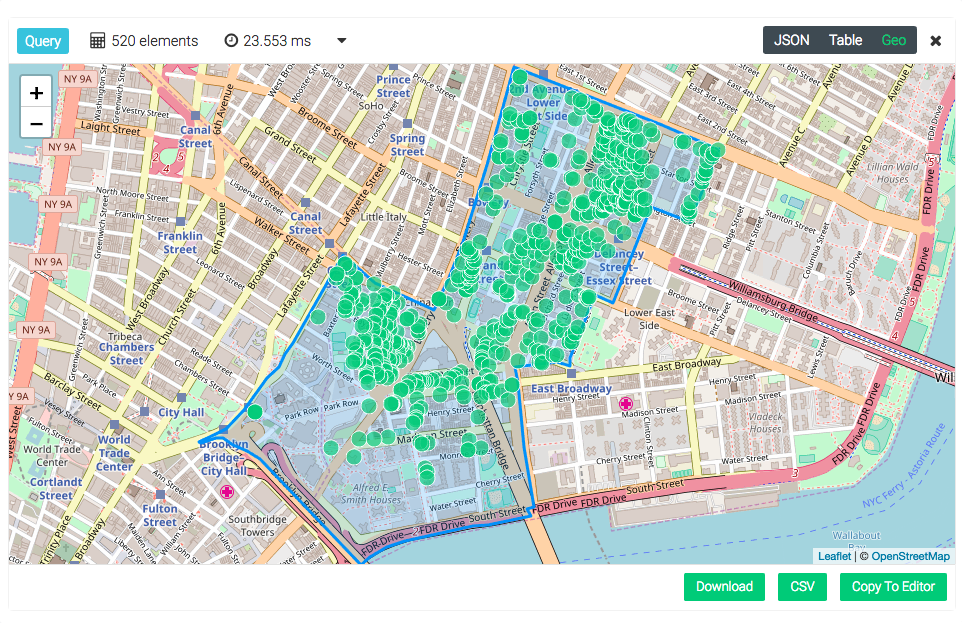
A little add-on to the geo queries is the direct visualization of your results via OpenStreetMap which helps to quickly navigate through your results.
New Query Profiler
Optimizing complex queries can be time-consuming. To simplify the process, we created the AQL Query Profiler. It shows the complete query profile, including detailed runtime statistics regarding the time spent in each stage of the query. With the new AQL Query Profiler, you can make an informed decision about potential optimizations by adding indexes, recompose your query or optimize your data structure. The displayed execution plan contains three new columns:
- Call, the number of times each query stage was executed;
- Items, the number of temporary result rows for a given stage;
- Runtime, the total time spent in the stage.
The Query Profiler can be used in the shell via db._profileQuery( ) or by clicking on the Profile button within the Query tab of the WebUI.
Learn more about query optimization and the profiler with the AQL Query Profiler tutorial.
In contrast to the “Explain” command, the “Profiler” executes a query and shows the actual time spend on each step of your AQL query. We hope this further helps to simplify query optimization.
Query Profiler Output (Console)
")
Query Profiler Output (WebUI)
")
New Streaming Cursors in ArangoDB
Over the past few months, we received many requests to find a way to achieve much faster response times to queries which return many results. In response to these requests, we added Streaming Cursors to ArangoDB.
With a cursor set to stream, you can now grab results as they are calculated on the server; you don’t have to wait for the query to be fully executed and thereby display results to a user much faster. Furthermore, it is possible to query results that are larger than the memory of a single coordinator with a streaming cursor. We hope these make a users’ life easier.
Cluster Experience Improvements
Over the past couple of years we improved and enriched the ArangoDB cluster capabilities. Although we’re aware that it will never be perfect, it doesn’t keep us from making improvements with each release. If you’re using ArangoDB in a cluster and upgrade to version 3.4, you will benefit from our engineer’s hard work.
Improvements have been implemented across the feature spectrum—not only to prevent unwanted behavior, but also for a much faster cluster startup, faster synchronization and faster query execution. Internal protocols and request handling has been intensively overhauled: Distributed Collect is just one example of cluster-wide query execution improvements.
For Version 3.4, we have overhauled the internal workings of the cluster for maintenance, failover and collection management. This has resulted in improved stability in edge cases as well as faster operation. The following video illustrates this by showing the creation of 20 replicated collections in both 3.3 and 3.4 side by side:
This higher performance will be noticeable for various day-to-day operations like shards getting in sync or being moved.
Additionally, with the recently released ArangoDB Kubernetes operator, deploying an ArangoDB cluster in k8s is as easy as issuing the command kubectl apply -f cluster.yaml with a 7 line YAML file, all the rest is done by Kubernetes and our operator automatically. Upgrading a complete deployment without any service interruption is done by nothing but editing the Docker image name in a YAML file. Read more about the ArangoDB Kubernetes Operator or go through this quick tutorial to get started.
RocksDB ON
The Default Storage Engine is now RocksDB
New installations of ArangoDB, starting with 3.4 will have RocksDB as the default storage engine. If you upgrade from a previous version, though, the default storage engine will be the one you set previously.
We have put plenty of work into optimizing our RocksDB integration, making it faster and extending the configuration possibilities. Below is a brief list of the most important changes:
- Optimized Binary Storage Format
The new format is optimized for RocksDB and can be utilized with new installations. A key benefit of the new format is greatly improved insertion performance. - Optional Caching
Users can now specify a new per-collection property, cacheEnabled to define documents and primary index values to be cached in memory. This leads to significant performance improvements for multiple cases, especially for point-lookups - Reduced Replication Catch-Up time
Much was optimized for a better replication experience for auto-failover, cluster and DC2DC settings.
Many more optimizations have been put in making our RocksDB integration worthy of being the default storage engine. We think you will be pleased by them.
In summary, ArangoDB 3.4 provides more than forty optimizations and improvements. We hope that everyone will benefit from the new release. Enjoy and please let us know your thoughts.
Download ArangoDB 3.4 Community or Enterprise Edition and try out the new features.
Get the latest tutorials, blog posts and news: