 Skip to content
Skip to content 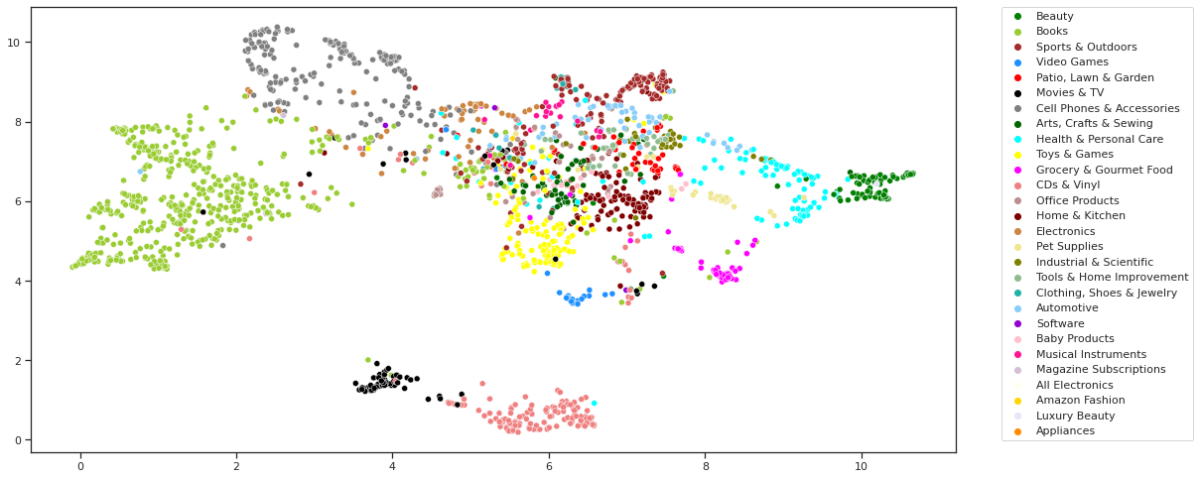
A Comprehensive Case-Study of GraphSage using PyTorchGeometric and Open-Graph-Benchmark
Estimated reading time: 15 minute
This blog post provides a comprehensive study on the theoretical and practical understanding of GraphSage, this notebook will cover:
- What is GraphSage
- Neighbourhood Sampling
- Getting Hands-on Experience with GraphSage and PyTorch Geometric Library
- Open-Graph-Benchmark’s Amazon Product Recommendation Dataset
- Creating and Saving a model
- Generating Graph Embeddings Visualizations and Observations
ArangoML Series: Multi-Model Collaboration
Estimated reading time: 8 minutes
Multi-Model Machine Learning
This article looks at how a team collaborating on a real-world machine learning project benefits from using a multi-model database for capturing ML meta-data.
The specific points discussed in this article are how:
- The graph data model is superior to relational for ML meta-data storage.
- Storing ML experiment objects is natural with multi-model.
- ArangoML promotes collaboration due to the flexibility of multi-model.
- ArangoML provides ops logging and performance analysis.

ArangoML Series: Intro to NetworkX Adapter
Estimated reading time: 3 minutes
This post is the fifth in a series of posts introducing the ArangoML features and tools. This post introduces the NetworkX adapter, which makes it easy to analyze your graphs stored in ArangoDB with NetworkX.
In this post we:
- Briefly introduce NetworkX
- Explore the IMDB user rating dataset
- Showcase the ArangoDB integration of NetworkX
- Explore the centrality measures of the data using NetworkX
- Store the experiment with arangopipe
This notebook is just a slice of the full-sized notebook available in the ArangoDB NetworkX adapter repository. It is summarized here to better fit the blog post format and provide a quick introduction to using the NetworkX adapter.
Performance analysis with pyArango: Part III Measuring possible capacity with usage Scenarios
ArangoDB | PyArango Performance Analysis – Transaction Inspection
Following the previous blog post on performance analysis with pyArango, where we had a look at graphing using statsd for simple queries, we will now dig deeper into inspecting transactions. At first, we split the initialization code and the test code.
Initialisation code
We load the collection with simple documents. We create an index on one of the two attributes: Read more
Performance analysis using pyArango Part I
This is Part I of Performance analysis using pyArango blog series. Please refer here for: Part II (cluster) and Part III (measuring system capacity).
Usually, your application will persist of a set of queries on ArangoDB for one scenario (i.e. displaying your user’s account information etc.) When you want to make your application scale, you’d fire requests on it, and see how it behaves. Depending on internal processes execution times of these scenarios vary a bit.
We will take intervals of 10 seconds, and graph the values we will get there:
- average – all times measured during the interval, divided by the count.
- minimum – fastest requests
- maximum – slowest requests
- the time “most” aka 95% of your users may expect an answer within – this is called 95% percentile
Wanted: Python API Contributors for NoSQL Project | ArangoDB Blog 2012
Are you a Python expert and want to contribute to an open source project? We need your help writing an API for Python for a new nosql database!
AvocadoDB is a rather new open source project – a fancy nosql database with a couple of interesting features:
- Schema-free schemata
- Usable as application server
- Consequent use of JavaScript
- multi-threaded
- Flexible data modeling (key value pairs, document store, graph database)
- Free index choice
- Configurable durability
- Support for modern storage hardware like SSD and large caches
You'll find more information on AvocadoDB here.
AvocadoDB is 100% open source using the Apache Licence 2.0.
Work in progress: general API and APIs for Ruby & PHP
Part of what we are currently doing is working on the APIs. AvocadoDB itself will provide
- a REST interface
- a query by example API
- a query language for more complex queries
Good news for the Ruby community: Thanx to @tisba, @moonbeamlabs and @a2800276, AvocadoDB will get a nice Ruby API and integration into Rails. Jan is implementing the PHP Api.
Python? Python!
Unfortunately we are no Python experts. Therefore we need the help of the community to support Python properly. We are looking for someone willing and able to develop a Python driver for AvocadoDB. It would be awesome to provide a document object manager like mongoEngine for Django as well (we would love to hear your thoughts on this – do you suggest anything else for Python?).
We have already compiled an „over the wire spec“ which describes the REST interface (attention: it’s work in progress and a few details will change in the next days).
Sounds all interesting? Join the team!
Do you want to become part of this project? Telling us how a proper implementation for Python should look like? Implementing? Great! :-) We would love to hear from you:
twitter: @fceller
email: hackers AT avocadodb.org
P.S. Are you a Java/Lua/C#/Whatever guy and would like AvocadoDB to support your language as well? YES! Ruby, Python and PHP is a good start, but we want to provide other languages as well, of course. So: Contact us as well! :-)