 Skip to content
Skip to content ArangoDB in 10 Minutes with Node.js: Quickstart Guide
Estimated reading time: 10 minutes
This is a short tutorial to get started with ArangoDB using Node.js. In less than 10 minutes you can learn how to use ArangoDB with Node. This tutorial uses a free ArangoDB Sandbox running on ArangoGraph that requires no sign up.
Let’s Get Started!
We will use the Repl live coding environment for the rest of the tutorial. This also requires no sign up and should already be ready to go. Read more
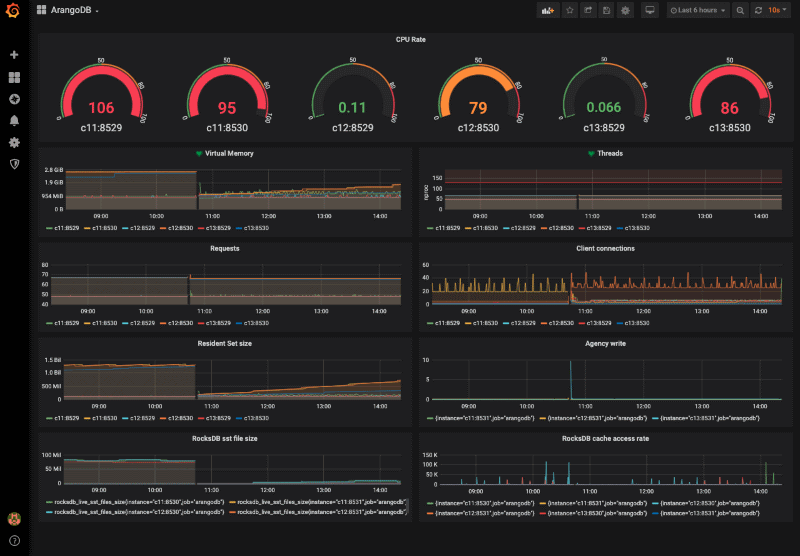
Monitoring ArangoDB with Promotheus and Grafana
Estimated reading time: 5 minutes
Please consider monitoring your productive ArangoDB installation as part of the best practices strategy. It is effortlessly done using established services Prometheus for data collection and Grafana for visualisation and alerting.
Celebrating Kube-ArangoDB’s 1.0 Release!
Estimated reading time: 4 minutes
Kube-ArangoDB, ArangoDB’s Kubernetes Operator first released two years ago and as of today is operating many ArangoDB production clusters (including ArangoDB’s Managed Service ArangoGraph). With many exciting features we felt kube-arango really deserves to be released as 1.0.
Public Preview of Microsoft Azure Now Available on ArangoDB Oasis
Estimated reading time: 3 minutes
Today we are excited to invite everybody to take the first public preview of Azure on ArangoDB Oasis for a test ride. In case you haven’t joined Oasis yet, please find more details about our offering and a 14-day free trial on cloud.arangodb.com. Just choose Microsoft Azure as your cloud provider and choose from the many regions we already support.
You can share all feedback with us about regions you’d love to see added or other improvements on slack. Please use the #oasis channel on Community Slack or raise an issue via the “Request Help” button in the bottom right corner of Oasis.
Please note that this is a public preview and not meant to be run in production.
Big Thanks to the Microsoft Azure Team
Before we dive into the details of the public preview for Azure on Oasis, we’d like to take a minute to send a big “Thank You!” to the Microsoft Azure team. The responsiveness and quality of their support as well as motivation to help us succeed has been exemplary. When building complex systems everything can’t be perfect but the support of the many different people at Azure has been. Thanks for making it possible to share the Oasis Azure offering so quickly with our community!
Azure on ArangoDB Oasis: That’s in
In this public preview, you can test the full feature set of ArangoDB Oasis on Azure for your projects. We already support a range of Azure regions including
- East US, Virginia: eastus2
- West US, Washington: westus2
- Central Canada, Toronto: canadacentral
- West Europe, Netherlands: westeurope
- UK, London: uksouth
We based the initial regions on customer feedback and can easily add more if you require them. Just use the “Request Help” button in the bottom right corner of Oasis and raise an issue for your preferred region.
Azure Pricing on Oasis
Azure will have a similarly low prices to get started with as ArangoDB Oasis on Google Cloud or AWS. You can get started with as little as $0,27/hour for a 3 node, highly available OneShard setup with 4GB memory and 10GB storage per node.
Please see detailed prices for various setups on the pricing page within Oasis.
Limitations within the Public Preview
Until we can declare Azure on Oasis production-ready, there is still one thing to be fixed. Currently, it is not possible to change the disk size after a deployment has been created. This is something which we want to fix within the next couple of weeks. In case you have an account of type “professional”, you can use a slider to configure the disk size. We also recommend that you only choose well-known values for the disk size.
You can get started with Oasis easily and for free. Just sign-up for Oasis and create your first deployment with just a few clicks. The first 14 days are on the house. No credit card needed. Test-run ends automatically after 14 days of use.
Get started with Oasis on Azure, Google Compute or AWS
Continue Reading
An Introduction to Geo Indexes and their performance characteristics: Part I
ArangoDB 3.3 GA
DC2DC Replication, Encrypted backup, Server-Level Replication and more
Alpha 1 of the upcoming ArangoDB 3.7
Estimated reading time: 6 minutes
We released ArangoDB version 3.6 in January this year, and now we are already 6 weeks into the development of its follow-up version, ArangoDB 3.7. We feel that this is a good point in time to share some of the new features of that upcoming release with you!
We try not to develop new features in a vacuum, but want to solve real-world problems for our end users. To get an idea of how useful the new features are, we would like to make alpha releases available to everyone as soon as possible. Our goal is get early user feedback during the development of ArangoDB, so we can validate our designs and implementations against the reality, and adjust them if it turns out to be necessary.
If you want to give some of the new features a test drive, you can download the 3.7 Alpha 1 from here – Community and Enterprise – for all supported platforms. Read more
Neo4j Fabric: Scaling out is not only distributing data
Estimated reading time: 3 minutes
Neo4j, Inc. is the well-known vendor of the Neo4j Graph Database, which solely supports the property graph model with graphs of previously limited size (single server, replicated).
In early 2020, Neo4j finally released its 4.0 version which promises “unlimited scalability” by the new feature Neo4j Fabric. While the marketing claim of “scalability” is true seen from a very simplistic perspective, developers and their teams should keep a few things in mind – most importantly: True horizontal scalability with graph data is not achieved by just allowing distributing data to different machines. Read more
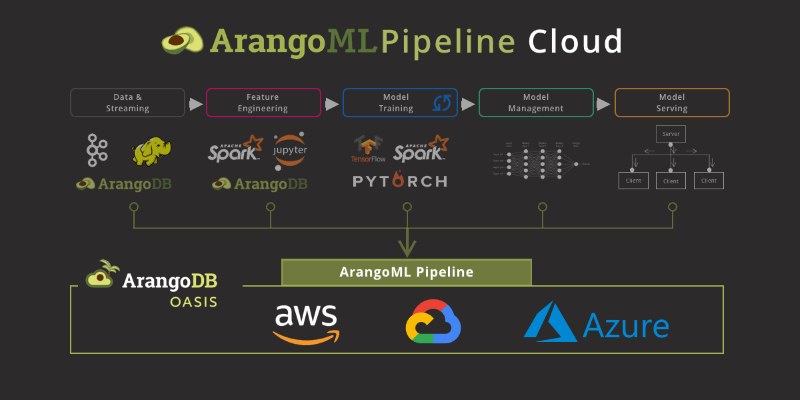
ArangoML Pipeline Cloud – Managed Machine Learning Metadata Service
Estimated reading time: 4 minutes
We all know how crucial training data for data scientists is to build quality machine learning models. But when productionizing Machine Learning, Metadata is equally important.
Consider for example:
- Capture of Lineage Information (e.g., Which dataset influences which Model?)
- Capture of Audit Information (e.g, A given model was trained two months ago with the following training/validation performance)
- Reproducible Model Training
- Model Serving Policy (e.g., Which model should be deployed in production based on training statistics)
If you would like to see a live demo of ArangoML Pipeline Cloud, join our Head of Engineering and Machine Learning, Jörg Schad, on February 13, 2020 – 10am PT/ 1pm ET/ 7pm CET for a live webinar.
This is the reason we built ArangoML Pipeline, a flexible Metadata store which can be used with your existing ML Pipeline. ArangoML Pipeline can be used as a simple extension of existing ML pipelines through simple python/HTTP APIs.
Check out this page for further details on the challenge of Metadata in Machine Learning and ArangoML Pipeline.
ArangoML Pipeline Cloud
Today we are happy to announce a first version of Managed ML Metadata. Now you can start using ArangoML Pipeline without having to even start a separate docker container.
Additionally, as a cloud-based service based on ArangoDB’s managed cloud service Oasis, it can be up & running in just a few clicks and in the Free-to-Try tier even without a lengthy registration.
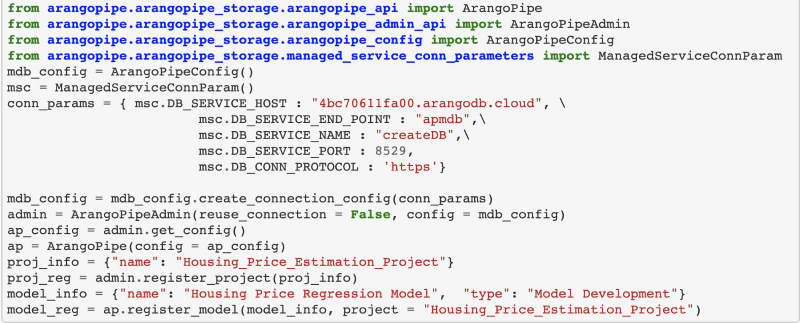
If you already have an existing notebook for your Machine Learning project it is as simple as adding the ArangoML Pipeline configuration pointing to our Free-to-Try tier `arangoml.arangodb.cloud` and a dedicated environment (aka ArangoDB database with custom login credentials) will be generated for you and persisted in the config.
SLAs
ArangoML Pipeline Cloud currently comes with two different service levels:
- Free-to-Try
The Free-to-Try tier allows for a no-hassle setup as it automatically configures your own environment based on a simple API call shown above and is ideas to test ArangoML Pipeline Cloud, but comes with no guarantees for your production data. - Production
If you are considering to use ArangoML Pipeline Cloud for production setup this is- Own Oasis cluster with all of Oasis Enterprise features
- Regular Backup
- It comes with a free 14-day trial period and afterwards follows the Oasis pricing model
Please reach out to arangoml@arangodb.cloud for sign-up and details.
How to get started
To show how easy it is to get started with ArangoML Pipeline Cloud in your existing ML pipeline we have a notebook with a modified TensorFlow Tutorial example with no setup or signup required!
If you are already using ArangoML Pipeline and just want to check how to migrate to ArangoML Pipeline Cloud we suggest to take a look at the minimal minimal example notebook.
While these notebook are mostly focused on the storing of metadata, we have a number of exciting notebooks with use-cases of how to further leverage and analyze metadata including for example datashift analysis.
Learn more:
- Learn more by checking out our example notebook on Google Colab
- Checkout the examples directory in our open source repository.
- Find here a tutorial notebook to get started with ArangoML Pipeline
- Learn more about using Arangopipe with common components of a machine learning stack like Tensorflow, hyperopt and pytorch
- Learn more about ArangoML Pipeline: Visit the blog
- To join a webinar for a live demo of how ArangoML Pipeline Cloud works: Register here
Continue Reading
InfoCamere investigated graph databases and chose ArangoDB
Performance analysis with pyArango: Part III Measuring possible capacity with usage Scenarios
Milestone 2 ArangoDB 3.3 – New Data Replication Engine and Hot Standby
Efficient Massive Inserts into ArangoDB with Node.js
Estimated reading time: 3 minutes
Nothing performs faster than arangoimport and arangorestore for bulk loading or massive inserts into ArangoDB. However, if you need to do additional processing on each row inserted, this blog will help with that type of functionality.
If the data source is a streaming solution (such as Kafka, Spark, Flink, etc), where there is a need to transform data before inserting into ArangoDB, this solution will provide insight into that scenario as well. Read more
What’s new in ArangoDB 3.6: OneShard Deployments and Performance Improvements
Estimated reading time: 9 minutes
Welcome 2020! To kick off this new year, we are pleased to announce the next version of our native multi-model database. So here is ArangoDB 3.6, a release that focuses heavily on improving overall performance and adds a powerful new feature that combines the performance characteristics of a single server with the fault tolerance of clusters.
If you would like to learn more about the released features in a live demo, join our Product Manager, Ingo Friepoertner, on January 22, 2020 - 10am PT/ 1pm ET/ 7pm CET for a webinar on "What's new in ArangoDB 3.6?".
Need to know more about multi-model?
tl;dr: Highlights of ArangoDB 3.6:
- OneShard Feature
- Performance Optimizations
- Subquery acceleration (up to 30x)
- Late document materialization
- Early pruning of non-matching documents
- Parallel AQL execution in clusters
- Streamlined update and replace queries
- ArangoSearch Enhancements
- New Cloud Service Pricing Model
ArangoDB 3.6 is also available on ArangoDB ArangoGraph - the cloud service for ArangoDB. Start your free 14-day trial today!
You will not regret upgrading to 3.6, as it most likely will improve your experience with your existing ArangoDB setup.
In 3.6 we concentrated strongly on performance optimizations for the everyday use of ArangoDB, and we picked the ones with the biggest impact first. As many users as possible should experience notable improvements and there is more in the pipeline for future releases.
Subquery performance has been improved up to 30 times, parallel execution of AQL queries allow to significantly reduce gathering time of data distributed over several nodes, and late document materialization reduces the need to retrieve non-relevant documents completely. Simple UPDATE and REPLACE operations that modify multiple documents are more efficient because several processing steps have been removed. The performance package is rounded off by an early pruning of non matching documents, essentially by directly applying the filter condition when scanning the documents, so that copying documents that do not meet the filter condition into the AQL scope can be avoided. Read more details in the AQL Subquery Benchmark or in the feature descriptions further on in this blog post.
The feature with probably the greatest impact is OneShard. Available in the Enterprise Edition of ArangoDB, customers can run use cases such as Graph Analytics on a single database node, with high availability and synchronous replication. Because the data is not distributed across multiple nodes, the graph traversal can be efficiently performed on a single node. The OneShard Cluster deployments are also available from our managed service, ArangoDB ArangoGraph.
With every release, we also improve the capabilities of ArangoSearch, our integrated full-text search engine with ranking capabilities. In 3.6 we have added support for edge n-grams to the existing Text Analyzer to support word-based auto-completion queries, improved the n-gram Analyzer with UTF-8 support and the ability to mark the beginning/end of the input sequence. ArangoSearch now also supports expressions with array comparison operators in AQL, and the `TOKENS()` and `PHRASE()` functions accept arrays. Both features enable dynamic search expressions.
If you are working with Dates you should know that AQL in 3.6 enforces a valid date range for working with date/time in AQL. This restriction allows for faster date calculation operations.
Of course, there are many other small features and improvements under the hood that you can leverage, please have a look at the Release Notes and the Changelog for all details.
ArangoDB 3.6 is already available on our Managed Cloud Service ArangoDB ArangoGraph, which offers you enterprise-quality ArangoDB clusters on AWS, Google Compute and soon Azure as well. Take ArangoDB 3.6 for a spin there with just a few clicks. First 14 days are on us!
New Cloud Service Pricing Model
In parallel to the 3.6 release, we are pleased to introduce also a new, attractive pricing system for ArangoDB ArangoGraph. You can now have your own highly available and scalable deployment from as little as $0.21 per hour (3 nodes, 4 GB RAM & 10 GB memory).
Some sample configurations for a 3-node OneShard deployment and their starting prices are listed in the table below (Please find the exact price for your desired setup within your ArangoGraph Account).
| Memory per node | Storage per node | Starting at |
| 4GB | 10GB | $0.21/hour |
| 8GB | 20GB | $0.52/hour |
| 16GB | 40GB | $0.91/hour |
| 32GB | 80GB | $1.74/hour |
| 64GB | 160GB | $3.42/hour |
| 128GB | 320GB | $6.52/hour |
The team worked very hard to further reduce the footprint of ArangoGraph sidecars, optimize the use of cloud resources and automate the modern ArangoGraph deployment process. In addition, we have been able to ramp up far more customers than expected in recent weeks, allowing us to pass on lower cloud costs and add support for more regions.
We hope that ArangoGraph is now an even better solution for more in the community and will continue to drive prices down further.
Register for the Webinar "What's new in ArangoDB 3.6" on January, 22nd, 2020 - 10am PT/ 1pm ET/ 7pm CET to see a live demo of newly released features.
For those who are curious what the features are about, here are some highlights with a brief description:
OneShard (Enterprise Edition)
Not all use cases require horizontal scalability. In such cases, a OneShard deployment offers a practicable solution that enables significant performance improvements by massively reducing cluster-internal communication.
 A database created with OneShard enabled is bound to a single DB-Server node but still replicated synchronously on other nodes to ensure resilience. This configuration allows running transactions with ACID guarantees on shard leaders.
A database created with OneShard enabled is bound to a single DB-Server node but still replicated synchronously on other nodes to ensure resilience. This configuration allows running transactions with ACID guarantees on shard leaders.
This setup is highly recommended for most Graph use cases and join-heavy queries.
If an AQL query accesses only collections that are locally on the same DB-Server node, the whole execution is transferred from the Coordinator to the DB-Server.
The possibilities are a lot broader than this, so please continue to read more about multi-tenancy use cases, ACID transactions and mixed-mode in the OneShard documentation.
Early pruning of non-matching documents
ArangoDB 3.6 evaluates `FILTER` conditions on non-index attributes directly while doing a full collection scan or an index scan. Any documents that don't match the `FILTER` conditions will then be discarded immediately.
Previous versions of ArangoDB needed to copy the data of non-matching documents from the scan operation into some buffers for further processing and finally filtering them.
With this scanning and filtering now happening in lockstep, queries that filter on non-index attributes will see a speedup. The speedup can be quite substantial if the `FILTER` condition is very selective and will filter out many documents, and/or if the filtered documents are large.
For example, the following query will run about 30 to 50% faster in 3.6 than in 3.5:
FOR doc IN collection
FILTER doc.nonIndexedValue == "test123456"
RETURN doc
(Mileage may vary depending on actual data, the tests here were done using a single server deployment with the RocksDB storage engine using a collection with one million documents that only have a single (non-indexed) `nonIndexedValue` attribute with unique values).
Subquery Performance Optimization
Subquery splicing inlines the execution of certain subqueries using a newly introduced optimizer rule. On subqueries with few results per input, the performance impact is significant.
Here is a self-join example query:
FOR c IN colC
LET sub = (FOR s IN colS FILTER s.attr1 == c.attr1 RETURN s)
RETURN LENGTH(sub)
Inlining this basic subquery yields to 28x faster query execution time in a cluster setup and a collection of 10k documents.
Explore further details in his Subquery Performance Benchmark.
Late document materialization (RocksDB)
Queries that use a combination of `SORT` and `LIMIT` will benefit from an optimization that uses index values for sorting first, then applies the `LIMIT`, and in the end only fetches the document data for the documents that remain after the `LIMIT`.
Sorting will be done on the index data alone, which is often orders of magnitude smaller than the actual document data. Sorting smaller data helps reducing memory usage and allocations, utilize caches better etc. This approach is often considerably faster than fetching all documents first, then sorting all of them using their sort attributes and then discarding all of them which are beyond the `LIMIT` value.
Queries, as follows, could see a substantial speedup:
FOR doc IN collection
FILTER doc.indexedValue1 == "test3"
SORT doc.indexedValue3
LIMIT 100
RETURN doc
The speedup we observed for this query is about 300%. For other queries we have seen similar speedups.
(Mileage may vary depending on actual data, the tests here were done using a single server deployment with the RocksDB storage engine using a collection with one million documents and a combined index on attributes `indexedValue1`, `indexedValue2` and `indexedValue3`. There were 10 distinct values for `indexedValue1`).
That optimization is applied for collections when using the RocksDB storage engine and for ArangoSearch views.
Parallel Execution of AQL Queries
ArangoDB 3.6 can parallelize work in many cluster AQL queries when there are multiple database servers involved. For example, if the shards for a given collection are distributed to 3 different database servers, data will be fetched concurrently from the 3 database servers that host the shards' data. The coordinator will then aggregate the results from multiple servers into a final result.
Querying multiple database servers in parallel can reduce latency of cluster AQL queries a lot. For some typical queries that need to perform substantial work on the database servers we have observed speedups of 30 to 40%.
The actual query speedup varies greatly, depending on the cluster size (number of database servers), number of shards per server, document count and size, plus result set size.
Parallelization is currently restricted to certain types of queries. These restrictions may be lifted in future versions of ArangoDB.
Optimizations for UPDATE and REPLACE queries
Cluster query execution plans for simple `UPDATE` and `REPLACE` queries that modify multiple documents and do not use `LIMIT` will now run more efficiently, as the optimizer can remove several execution steps automatically. Removing these steps reduces the cluster-internal traffic, which can greatly speed up query execution times.
For example, a simple data-modification query such as:
FOR doc IN collection
UPDATE doc WITH { updated: true } IN collection
Here we could remove one intermediate hop to the coordinator, which also makes the query eligible for parallel execution. We have seen speedups of 40% to 50% due to this optimization, but the actual mileage can vary greatly depending on sharding setup, document size and capabilities of the I/O subsystem.
The optimization will automatically be applied for simple `UPDATE`, `REPLACE` and `REMOVE` operations on collections sharded by `_key` (which is the default), provided the query does not use a `LIMIT` clause.
ArangoSearch Enhancements
We continuously improve the capabilities of ArangoSearch. The late document materialization mentioned accelerates the search by reading only necessary documents from the underlying collections.
Search conditions now support array comparison operators with dynamic arrays as left operand:
LET tokens = TOKENS("some input", "text_en") // ["some", "input"]
FOR doc IN myView SEARCH tokens ALL IN doc.title RETURN doc // dynamic conjunction
FOR doc IN myView SEARCH tokens ANY IN doc.title RETURN doc // dynamic disjunction
FOR doc IN myView SEARCH tokens NONE IN doc.title RETURN doc // dynamic negation
FOR doc IN myView SEARCH tokens ALL > doc.title RETURN doc // dynamic conjunction with comparison
FOR doc IN myView SEARCH tokens ANY <= doc.title RETURN doc // dynamic disjunction with comparison
In addition, the `TOKENS()` and `PHRASE()` function can be used with arrays as parameter. For more information on the array support, see the release notes.
In ArangoDB 3.6 we have added edge n-gram support to the Analyzer type `text` of ArangoSearch. For each token (word) `edge n-grams` are generated. This means that the beginning of the `n-gram` is anchored to the beginning of the token, while the `ngram` analyzer would generate all possible substrings from a single input token (within the defined length restrictions).
Edge n-grams can be used to cover word-based auto-completion queries with an index.
UTF-8 support and the ability to mark the start/end of the sequence for the `n-gram` Analyzer type have been added. The marker is appended to `n-grams` and allows searching for these positions in tokens.
Example Analyzer and Query:
arangosh>analyzer.save("myNgram", "ngram", { min:2, max:3, startMarker: "^", endMarker: "$", streamType: "utf8"})
FOR d IN view x
SEARCH ANALYZER(d.category == "^new", "myNgram")
The marker "^" now restricts category results to those that begin with "new".
Take ArangoDB 3.6 for a test drive. Any feedback is, as always, highly appreciated! If you are upgrading from a previous version, check our General Upgrade Guide.
Join the “What is new in ArangoDB 3.6?” webinar to get a hands-on overview on the new features with our Product Manager, Ingo Friepoertner, on January 22, 2020 - 10am PT/ 1pm ET/ 7pm CET.
We hope you find many useful new features and improvements in ArangoDB 3.6. If you like to join the ArangoDB Community, you can do so on GitHub, Stack Overflow and Slack.
Continue Reading
Performance analysis with pyArango: Part II
Inspecting transactions
Release Candidate 2 of the ArangoDB 3.6 available for testing
We are working on the release of ArangoDB 3.6 and today, just in time for the holiday season, we reached the milestone of RC2. You can download and take the RC2 for a spin: Community Edition and Enterprise Edition.
The next version of the multi-model database will be primarily focused on major performance improvements. We have improved on many fronts of speeding up AQL and worked on things like:
- Subquery performance
- Parallel execution of AQL queries that allows to significantly reduce gathering time of data distributed over several nodes
- Late document materialization that reduces the need to retrieve non-relevant documents completely
- `UPDATE` and `REPLACE` operations
- Early pruning of non matching documents that directly applies the filter condition when scanning the documents, so that copying documents that do not meet the filter condition into the AQL scope can be avoided
The new feature that will be generally available with ArangoDB 3.6 Enterprise Edition is OneShard.
Not all use cases require horizontal scalability. In such cases, a OneShard deployment offers a practicable solution that enables significant performance improvements by massively reducing cluster-internal communication. A database created with OneShard enabled is limited to a single DB-Server node but still replicated synchronously to ensure resilience. This configuration allows running transactions with ACID guarantees on shard leaders.
Read more about this feature in our documentation. You can already try out the benefits of OneShard by testing the Enterprise Edition Release Candidate 2. If you have ArangoDB installed, please remember to backup your data and run an upgrade after installing the RC release.
With every release of ArangoDB, we are continuously working on improvements in ArangoSearch - our full-text search engine including similarity ranking capabilities. With the upcoming ArangoDB 3.6 we have added support for edge n-grams to the existing Text Analyzer to support word-based auto-completion queries. The n-gram Analyzer was also enhanced with UTF-8 support and the ability to mark the beginning/end of the input sequence. Two new features that enable dynamic search expressions were also added: the `TOKENS()` and `PHRASE()` functions accept arrays and expressions with array comparison operators in AQL.
For the full list of features and improvements that are going to be introduced with the upcoming ArangoDB 3.6 check out the Release Notes or the Changelog.
Happy testing and it would be fantastic to hear about your feedback via Github.
Get the latest tutorials,
blog posts and news: