 Skip to content
Skip to content Entity Resolution in ArangoDB
Estimated reading time: 8 minutes
This post will dive into the world of Entity Resolution in ArangoDB. This is a companion piece for our Lunch and Learn session, Graph & Beyond Lunch Break #15: Entity Resolution.
In this article we will:
- give a brief background in Entity Resolution (ER)
- discuss some use-cases for ER
- discuss some techniques for performing ER in ArangoDB
Inside the Avocado Grove: From Canada to Germany and the Digital Marketing of Avocados
Estimated reading time: 8 minutes
My name is Laura, and I am responsible for digital marketing here at ArangoDB.
In the following post, I will dive into my own experience working at ArangoDB and how I ended up from Northern Ontario, Canada to work in Germany at a native multi-model graph database company. Are you interested in learning more about working abroad, working remotely, or diving into a new industry? This post covers all of the above topics.
(more…)Word Embeddings in ArangoDB
Estimated reading time: 12 minute
This post will dive into the world of Natural Language Processing by using word embeddings to search movie descriptions in ArangoDB.
In this post we:
- Discuss the background of word embeddings
- Introduce the current state-of-the-art models for embedding text
- Apply a model to produce embeddings of movie descriptions in an IMDb dataset
- Perform similarity search in ArangoDB using these embeddings
- Show you how to query the movie description embeddings in ArangoDB with custom search terms
Introducing Developer Deployments on ArangoDB ArangoGraph
Estimated reading time: 4 minutes
Today we’re announcing the introduction of Developer deployments as a beta feature on the Oasis platform.
In this blog post, we’ll tell you what Developer deployments are, what you can do with them, what you should not do with them, and how to get started.
What are Developer deployments?
Since we launched Oasis, a deployment on Oasis has always been a highly available ArangoDB cluster. That is great for high availability, and it allows you to scale your deployment to incredibly large sets of data.
Many customers have told us that they would like something a bit smaller that can be used by an individual developer, or better yet, let every developer have their own deployment.
That request is exactly what we are answering with the introduction of Developer deployments.
A Developer deployment consists of only a single server on a single node.
With that configuration, there is obviously no high availability, and scaling is limited to vertical scaling of that single server.
For those reasons, Developer deployments are not suitable for any kind of production environment, and because of that, Developer deployments are excluded from audit logs.
Support is given for Developer deployments on a best effort basis. It is not possible to buy an additional support plan with a Developer deployment.
All other features, like backups, full encryption, and Foxx, are fully available.
What can you do with a Developer deployment?
Developer deployments are ideal when you want to experiment with ArangoDB, or are just learning its features.
They are also ideal for (small scale) analytics experiments. You can quickly load your data into them, configure your graphs and perform your analysis.
The lack of high availability is usually not a problem for such experiments.
Of course, you can also give a single Developer deployment to all of your developers to develop an application against. When you do so, you have to keep in mind that there are small differences between a single instance of ArangoDB and a cluster.
Within Oasis, we have reduced these changes by requiring the use of the WITH statement in exactly the same way that a cluster deployment requires that keyword (from ArangoDB version 3.7.12 and higher).
How are Developer deployments priced?
A Developer deployment launched in AWS Ohio is available for as little as $ 0.058 per hour or $42.2 per month. The same deployment with General CPU is available for $ 0.068 per hour.
Similar to our OneShard and Sharded deployments, network traffic and backup storage is charged separately.
For more details on pricing, please log in to the Oasis dashboard and visit the Pricing page.
What not do with Developer deployments
As mentioned before, Developer deployments are not highly available and can be restarted at any time. For that reason, you should not use them for any kind of production environment.
Since we strongly believe that a staging environment should reflect the production environment as much as possible, you should also not use a Developer deployment for a staging environment.
How to get started with Developer deployments
To create a Developer deployment on Oasis, log in to your ArangoDB Oasis account on cloud.arangodb.com.
Then go to your project and click on New Deployment.

Enter all the normal fields such as the name of your deployment and select a cloud provider & region.
Then click on the Developer (beta) button to choose the Developer model.
![]()
Select the size of your deployment and click on Create.

Your Developer deployment will now bootstrap.
Once that has finished, you’ll receive an email and can start to use your deployment.
Hear More from the Author
OCB: Challenges in Building Multi-Cloud-Provider Platform With Kubernetes
Getting Started with ArangoDB Oasis
Continue Reading
ArangoML Part 1: Where Graphs and Machine Learning Meet
A story of a memory leak in GO: How to properly use time.After()
ArangoBNB Data Preparation Case Study: Optimizing for Efficiency
Estimated reading time: 18 minutes
This case study covers a data exploration and analysis scenario about modeling data when migrating to ArangoDB. The topics covered in this case study include:
- Importing data into ArangoDB
- Developing Application Requirements before modeling
- Data Analysis and Exploration with AQL
This case study can hopefully be used as a guide as it shows step-by-step instructions and discusses the motivations in exploring and transforming data in preparation for a real-world application.
The information contained in this case study is derived from the development of the ArangoBnB project; a community project developed in JavaScript that is always open to new contributors. The project is an Airbnb clone with a Vue frontend and a React frontend being developed in parallel by the community. It is not necessary to download the project or be familiar with JavaScript for this guide. To see how we are using the data in a real-world project, check out the repository.
Data Modeling Example
Data modeling is a broad topic and there are different scenarios in practice. Sometimes, your team may start from scratch and define the application’s requirements before any data exists. In that case, you can design a model from scratch and might be interested in defining strict rules about the data using schema validation features; for that topic, we have an interactive notebook and be sure to see the docs. This guide will focus on the situation where there is already some data to work with, and the task involves moving it into a new database, specifically ArangoDB, as well as cleaning up and preparing the data to use it in a project.
Preparing to migrate data is a great time to consider new features and ways to store the data. For instance, it might be possible to consolidate the number of collections being used or store the data as a graph for analytics purposes when coming from a relational database. It is crucial to outline the requirements and some nice-to-haves and then compare those to the available data. Once it is clear what features the data contains and what the application requires, it is time to evaluate the database system features and determine how the data will be modeled and stored.
So, the initial steps we take when modeling data include:
- Outline application requirements and optional features
- Explore the data with those requirements in mind
- Evaluate the database system against the dataset features and application requirements
As you will see, steps 2 and 3 can easily overlap; being aware of database system features can give you ideas while exploring the data and vice versa. This overlap is especially common when using the database system to explore, as we do in this example.
For this example, we are using the Airbnb dataset initially found here. The dataset contains listing information scraped from Airbnb, and the dataset maintainer provides it in CSV and GeoJSON format.
The files provided, their descriptions, and download links are:
NOTE: The following links are outdated and interested parties should use the recent links available at InsideAirBnB
- Listings.csv.gz
- Detailed Listings data for Berlin
- Download Link
- Calendar.csv.gz
- Detailed Calendar Data for listings in Berlin
- Download Link
- Reviews.csv.gz
- Detailed Review Data for listings in Berlin
- Download Link
- Listings.csv
- Summary information and metrics for listings in Berlin (good for visualisations).
- Download Link
- Reviews.csv
- Summary Review data and Listing ID (to facilitate time based analytics and visualisations linked to a listing).
- Download Link
- Neighborhoods.csv
- Neighbourhood list for geo filter. Sourced from city or open source GIS files.
- Download Link
- Neighborhoods.geojson
- GeoJSON file of neighbourhoods of the city.
- Download Link
The download links listed here are for 12-21-2020, which we used just before insideairbnb published the 02-22-2021 links. If they don’t work for some reason, you can always get the updated ones from insideairbnb, but there is no guarantee that they will be compatible with this guide.
Application Requirements
Looking back at the initial steps we typically take, the first step is to outline the application requirements and nice-to-haves. One could argue that doing data exploration might be necessary before determining the application requirements. However, knowing what our application requires can inform decisions when deciding how to store the data, such as extracting or aggregating data from other fields to fulfill an application requirement.
For this step, we had multiple meetings where we outlined our goals for the application. We have the added benefit of already knowing the database system we will be using and being familiar with its capabilities.
There are a couple of different motivations involved in this project. For us, ArangoDB, we wanted to do this project to:
- Showcase the upcoming ArangoSearch GeoJSON features
- Provide a real-world full stack JavaScript application with a modern client-side frontend framework that uses the ArangoJS driver to access ArangoDB on the backend.
With those in mind, we continued to drill down into the actual application requirements. Since this is an Airbnb clone, we started by looking on their website and determining what was likely reproducible in a reasonable amount of time.
Here is what we started with:
- Search an AirBnB dataset to find rentals nearby a specified location
- A draggable map that shows results based on position
- Use ArangoSearch to keep everything fast
- Search the dataset using geographic coordinates
- Filter results based on keywords, price, number of guests, etc
- Use AQL for all queries
- Multi-lingual support
We set up the GitHub repository and created issues for the tasks associated with our application goals to define further the required dataset features. Creating these issues helps in thinking through the high-level tasks for both the frontend and backend and keeps us on track throughout.
Data Exploration
With our application requirements ready to go, it is time to explore the dataset and match the available data with our design vision.
One approach is to reach for your favorite data analysis tools and visualization libraries such as the Python packages Pandas, Plotly, Seaborn, or many others. You can look here for an example of performing some basic data exploration with Pandas. In the notebook, we discover the available fields, data types, consistency issues and even generate some visualizations.
For the rest of this section, we will look at how you can explore the data by just using ArangoDB’s tools, the Web UI, and the AQL query language. It is worth noting that there are many third-party tools available for analyzing data, and using a combination of tools will almost always be necessary. The purpose of this guide is to show you how much you can accomplish and how quickly you can accomplish it just using the tools built into ArangoDB.
Importing CSV files
First things first, we need to import our data. When dealing with CSV files, the best option is to use arangoimport. The arangoimport tool imports either JSON, CSV, or TSV files. There are different options available to adjust the data during import to fit the ArangoDB document model better. It is possible to specify things such as:
- Fields that it should skip during import
- Whether or not to convert values to non-string types (numbers, booleans and null values)
- Options for changing field names
System Attributes
Aside from the required options, such as server information and collection name, we will use the `--translate` option. We are cheating a little here for the sake of keeping this guide as brief as possible. We already know that there is a field in the listings files named id that is unique and perfectly suited for the _key system attribute. This attribute is automatically generated if we don’t supply anything, but can also be user-defined. This attribute is automatically indexed by ArangoDB, so having a meaningful value provided here means that we can perform quick and useful lookups against the _key attribute right away, for free.
In ArangoDB system attributes cannot be changed, the system attributes include:
- _key
- _id (collectionName/_key)
- _rev
- _from (edge collection only)
- _to (edge collection only)
For more information on system attributes and ArangoDB’s data model, see the guide available in the documentation. To set a new _key attribute later, once we have a better understanding of the available data, we would need to create a new collection and specify the value to use; we get to skip that step.
Importing Listings
For our example, we import the listings.csv.gz file, which per the website description, contains detailed listings data for Berlin.
The following is the command to run from the terminal once you have ArangoDB installed and the listings file unzipped.
arangoimport --file .\listings.csv --collection "listings" --type csv --translate "id=_key" --create-collection true --server.database arangobnb
Once the import is complete, you can navigate to the WebUI and start exploring this collection. If you are following along locally, the default URL for the WebUI is 127.0.0.1:8529.
Once you open the listings collection, you should see documents that look like this:
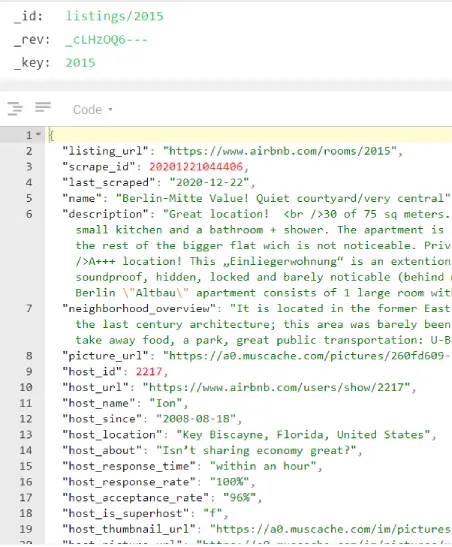
Analyzing the Data Structure
The following AQL query aggregates over the collection and counts the number of documents with that same field, what those fields are, and their data types. This query provides insight into how consistent the data is and can point out any outliers in our data. When running these types of queries it may be a good idea to supply a LIMIT to avoid aggregating over the entire collection, it depends on how important it is to check every single document in the collection.
FOR doc IN listings
FOR a IN ATTRIBUTES(doc, true)
COLLECT attr = a, type = TYPENAME(doc[a]) WITH COUNT INTO count
RETURN {attr, type, count}
Query Overview:
This query starts with searching the collection and then evaluates each document attribute using the ATTRIBUTES function. System attributes are deliberately ignored by setting the second argument to true. The COLLECT keyword signals that we will be performing an aggregation over the attributes of each document. We define two variables that we want to use in our return statement: the attribute name assigned to the `attr` variable and the type variable for the data types. Using the TYPENAME() function, we capture the data type for each attribute. With an ArangoDB aggregation, you can specify that you want to count the number of items by adding `WITH COUNT INTO` to your COLLECT statement followed by the variable to save the value into; in our case, we defined a `count` variable.
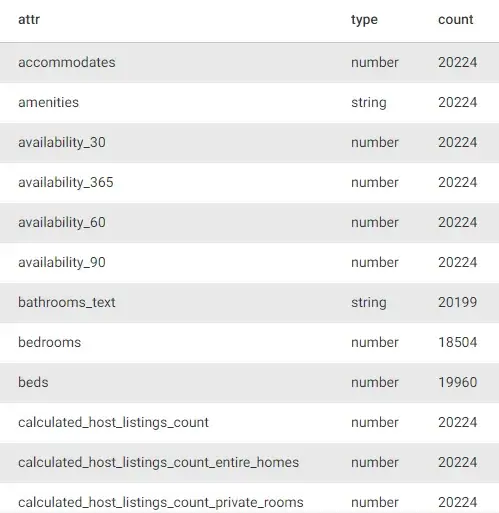
The results show that about half of the fields have a count of 20,224 (the collection size), while the rest have varying numbers. A schema-free database’s flexibility means understanding that specific values may or may not exist and planning around that. In our case, we can see that a good number of fields don’t have values. Since we are thinking about this data from a developer’s perspective, this will be invaluable when deciding which features to incorporate.
Data Transformations
The results contain 75 elements that we could potentially consider at this point, and a good place to start is with the essential attributes for our application.
Some good fields to begin with include:
- Accommodates: For the number of Guests feature
- Amenities: For filtering options such as wi-fi, hot tub, etc.
- Description: To potentially pull keywords from or for the user to read
- Review fields: For a review related feature
- Longitude, Latitude: Can we use this with our GeoJSON Analyzer?
- Name: What type of name? Why are two of the names a number?
- Price: For filtering by price
We have a lot to start with, and some of our questions will be answered easiest by taking a look at a few documents in the listings collection. Let’s move down the list of attributes we have to see how they could fit the application.
Accommodates
This attribute is pretty straightforward as it is simply a number, and based on our type checking; all documents contain a number for this field. The first one is always easy!
AmenitiesThe amenities appear to be arrays of strings, but encoded as JSON string. Being a JSON array is either a result of the scraping method used by insideAirbnb or placed there for formatting purposes. Either way, it would be more convenient to store them as an actual array in ArangoDB. The JSON_PARSE() AQL function to the rescue! Using this function, we can quickly decode and store the amenities as an array all at once.
FOR listing IN listings
LET amenities = JSON_PARSE(listing.amenities)
UPDATE listing WITH { amenities } IN listings
Query Overview:
This query iterates over the listings collection and declares a new `amenities` variable with the LET keyword. We finish the FOR loop by updating the document with the JSON_PARSE’d amenities array. The UPDATE operation replaces pre-existing values, which is what we want in this situation.
Description
Here is an example of a description of a rental location:

As you can see, this string contains some HTML tags, primarily for formatting, but depending on the application, it might be necessary to remove these characters to avoid undesired behavior. For this sort of text processing, we can use the AQL REGEX_REPLACE() function. We will be able to use this HTML formatting in our Vue application thanks to the v-html Vue directive, so we won’t remove the tags. However, for completeness, here is an example of what that function could look like:
FOR listing IN listingsRETURN REGEX_REPLACE(listing.description, "<[^>]+>\s+(?=<)|<[^>]+>", " ")
Query Overview:
This query iterates through the listings and uses REGEX_REPLACE() to match HTML tags and replaces them with spaces. This query does not update the documents as we want to make use of the HTML tags. However, you could UPDATE the documents instead of just returning the transformed text.
Reviews
For the fields related to reviews, it makes sense that they would have different numbers compared to the rest of the data. Some listings may have never had a review, and some will have more than others. The review data types are consistent, but not every listing has one. Handling reviews is not a part of our initial application requirements, but in a real-world setting, they likely would be. We had not discussed reviews during planning as this site likely won’t allow actual users to sign up for it.
Knowing that our data contains review information gives us options:
- Do we consider removing all review information from the dataset as it is unnecessary?
- Or, leave it and consider adding review components to the application?
This type of question is common when considering how to model data. It is important to consider these sorts of questions for performance, scalability, and data organization.
Eventually, we decided to use reviews as a way to sort the results. As of this writing, we have not implemented a review component that shows the reviews, but if any aspiring JavaScript developer is keen to make it happen, we would love to have another contributor on the project.
LocationWhen we started the project, we knew that this dataset contained location information. It is a dataset about renting properties in various locations, after all. The location data is stored as two attributes; longitude and latitude. However, we want to use the GeoJSON Analyzer which requires a GeoJSON object. We prefer to use GeoJSON as it can be easier to work with since, for example, the order of the coordinate pairs isn’t always consistent in datasets and the GeoJSON analyzer supports more than just points, should our application need that. Fortunately, since these values represent a single point, converting this data to a valid GeoJSON object is a cinch.
FOR listing IN listingsUPDATE listing._keyWITH {"location": GEO_POINT(listing.longitude, listing.latitude)}IN listings
Query Overview:
This query UPDATEs each listing with a new location attribute. The location attribute contains the result of the GEO_POINT() AQL function, which constructs a GeoJSON object from longitude and latitude values.
Note: Sometimes, it is helpful to see the output of a function before making changes to a document. To just see the result of an AQL function such as the GEO_POINT() function we used above, you could simply RETURN the result, like so:
FOR listing IN listings LIMIT 1 RETURN GEO_POINT(listing.longitude, listing.latitude)
Query Overview:
This query makes no changes to the original document. It simply selects the first available document and RETURNs the result of the GEO_POINT() function. This can be helpful for testing before making any changes.

Name
The name value spurred a couple of questions after the data type query that we will attempt to answer in this section.
- What is the purpose of the name field?
- Why are there numeric values for only 2 of them?
The first one is straightforward to figure out by opening a document and seeing what the name field contains. Here is an example of a listing name:
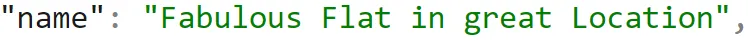
The name is the title or a tagline for the rental; you would expect to see it when searching for a property. We will want to use this for our rental titles, so it makes sense to dig a little deeper to find any inconsistencies. Let’s figure out why some have numeric values and if they should be adjusted. With AQL queries, sorting in ascending order starts with symbols and numbers; this gives us an easy option to look at the listings with numeric values for the name field. We will evaluate the documents more robustly in a moment but first, let’s just have a look.
FOR listing in listingsSORT listing.name ASCRETURN listing.name
Query Overview:
This query simply returns the listings sorted in ascending order. We explicitly declare ASC for ascending, but it is also the default SORT order.

We see the results containing the numbers we were expecting, but we also see some unexpected results; some empty strings for name values. Depending on how important this is to the application, it may be necessary to update these empty fields with something indicating a name was not supplied and perhaps also make it a required field for future listings.
If we return the entire listing, instead of just the name, they all seem normal and thus might be worth leaving in as they are still potentially valid options for renters.
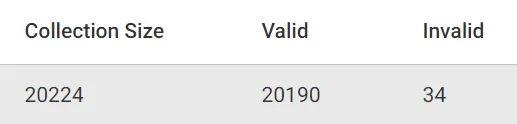
We know that we have 34 values with invalid name attributes with the previous results, but what if we were unsure of how many there are because they didn’t all show up in these results?
FOR listing in listingsFILTER HAS(listing, "name")ANDTYPENAME(listing.name) == "string"ANDlisting.name != ""COLLECT WITH COUNT INTO cRETURN {"Collection Size": LENGTH(listings),"Valid": c,"Invalid": SUM([LENGTH(listings), -c])}
Query Overview:
This query starts with checking that the document HAS() the name attribute. If it does have the name attribute, we check that the data type of the name value has a TYPENAME() of "string". Additionally, we check that the name value is not an empty string. Finally, we count the number of valid names and subtract them from the number of documents in the collection. This provides us with the number of valid and invalid listing names in our collection.
A developer could update this type of query with other checks to evaluate data validity. You could use the results of the above query to potentially motivate a decision for multiple things, such as:
- Is this enough of an issue to investigate further?
- Is there potentially a problem with my data?
- Do I need to cast these values TO_STRING() or leave them as is?
The questions of these depend on the data size and complexity, as well as the application.
Price
The final value we will take a look at is the price. Our data type results informed us that the price is a string, and while looking at the listings, we saw that they contain the dollar sign symbol.
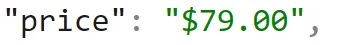
Luckily, ArangoDB has an AQL function that can cast values to numbers, TO_NUMBER().
FOR listing IN listingsUPDATE listing WITH{price: TO_NUMBER(SUBSTRING(SUBSTITUTE(listing.price, ",",""), 1))}IN listings
Query Overview:
There is kind of a lot going on with this query so let’s start by evaluating it from the inside out.
We begin with the SUBSTITUTE() function, checking for commas in the price (they are used as thousands separator). This step is necessary because the TO_NUMBER() function considers a value with a comma an invalid number and would set the price to 0.
Next, we need to get rid of the $ as it would also not be considered a valid number. This is where SUBSTRING() comes into play. SUBSTRING() allows for providing an offset number to indicate how many values we want to remove from the beginning of the string. In our case, we only want to remove the first character in the string, so we provide the number 1.
Finally, we pass in our now comma-less and symbol-less value to the TO_NUMBER() function and UPDATE the listing price with the numeric representation of the price.
As mentioned previously, it is sometimes helpful to RETURN values to get a better idea of what these transformations might look like before making changes. This query provides a better understanding of what exactly is happening in this query:
FOR listing IN listingsLIMIT 1RETURN {Price: listing.price,Substitute: SUBSTITUTE(listing.price, ",",""),Substring: SUBSTRING(SUBSTITUTE(listing.price, ",",""), 1),To_Number: TO_NUMBER(SUBSTRING(SUBSTITUTE(listing.price, ",",""), 1))}

Conclusion
Other fields could potentially be updated, changed, or removed, but those are all we will cover in this guide. As the application is developed, there will likely be even more changes that need to occur with the data, but we now have a good starting point.
Hopefully, this guide has also given you a good idea of the data exploration capabilities of AQL. We certainly didn’t cover all of the AQL functions that could be useful for data analysis and exploration but enough to get started. To continue exploring these, be sure to review the type check and cast functions and AQL in general.
Next Steps..
With the data modeling and transformations complete, some next steps would be to:
- Explore the remaining collections
- Configure a GeoJSON Analyzer
- Create an ArangoSearch View
- Consider indexing requirements
- Start building the app!
Hear More from the Author
Continue Reading
ArangoDB Assembles 10,000 GitHub Stargazers