 Skip to content
Skip to content Foxx CLI – Managing Microservices
Anyone who has ever worked with our JavaScript framework Foxx was faced at some point with the challenge to install its Foxx service in its current ArangoDB instance or to replace the installed service with local code changes. This is not a big deal and can easily be done through ArangoDB’s WebUI. However, we developers always want to become more productive and clicking through a graphical UI is not the best way. Furthermore, this procedure is almost impossible to use in an automated deployment process. That’s why we decided to develop a node-based CLI tool to manage Foxx services, called Foxx-CLI, which we already released in version 1.1.
Auto-Generate GraphQL for ArangoDB
Currently, querying ArangoDB with GraphQL requires building a GraphQL.js schema. This is tedious and the resulting JavaScript schema file can be long and bulky. Here we will demonstrate a short proof of concept that reduces the user related part to only defining the GraphQL IDL file and simple AQL queries.
The Apollo GraphQL project built a library that takes a GraphQL IDL and resolver functions to build a GraphQL.js schema. Resolve functions are called by GraphQL to get the actual data from the database. I modified the library in the way that before the resolvers are added, I read the IDL AST and create resolver functions.
To simplify things and to not depend on special "magic", let's introduce the directive `@aql`. With this directive, it's possible to write an AQL query that gets the needed data. With the bind parameter `@current` it is possible to access the current parent object to do JOINs or related operations.
Interested in trying out ArangoDB? Fire up your database in just a few clicks with ArangoDB ArangoGraph: the Cloud Service for ArangoDB. Start your free 14-day trial here.
A GraphQL IDL
type BlogEntry {
_key: String!
authorKey: String!
author: Author @aql(exec: "FOR author IN Author FILTER author._key == @current.authorKey RETURN author")
}
type Author {
_key: String!
name: String
}
type Query {
blogEntry(_key: String!): BlogEntry
}This IDL describes a `BlogEntry` and an `Author` object. The `BlogEntry` holds an `Author` object which is fetched via the AQL query in the directive `@aql`. The type Query defines a query that fetches one `BlogEntry`.
Now let's have a look at a GraphQL query:
{
blogEntry(_key: "1") {
_key
authorKey
author {
name
}
}
}This query fetches the `BlogEntry` with `_key` "1". The generated AQL query is:
FOR doc IN BlogEntry FILTER doc._key == '1' RETURN docAnd with the fetched `BlogEntry` document the corresponding `Author` is fetched via the AQL query defined in the directive.
The result will approximately look like this:
{
"data" : {
"blogEntry" : {
"_key" : "1",
"authorKey" : "2",
"author" : {
"name" : "Author Name"
}
}
}
}As a conclusion of this short demo, we can claim that with the usage of GraphQLs IDL, it is possible to reduce effort on the users' side to query ArangoDB with GraphQL. For simple GraphQL queries and IDLs it's possible to automatically generate resolvers to fetch the necessary data.
The effort resulted in an npm package is called graphql-aql-generator.
ArangoDB Foxx example
Now let’s have a look at the same example, but with using ArangoDB javascript framework - Foxx. To do so, we have to follow the simple steps listed below:
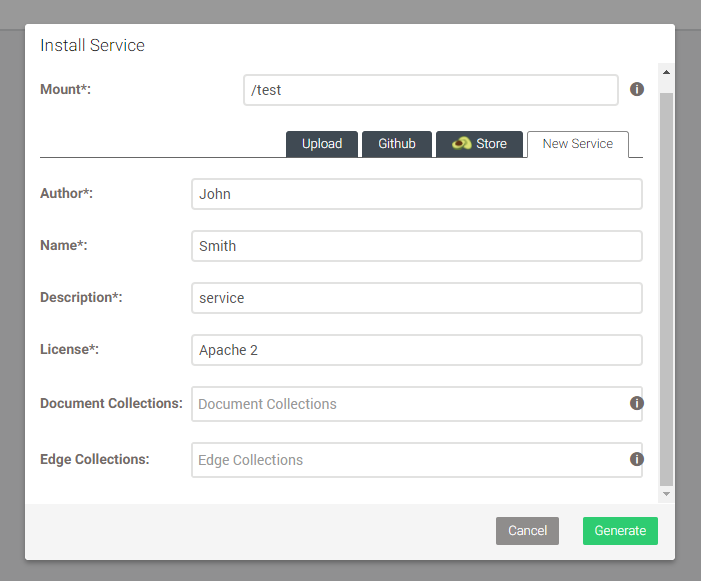
- Open the ArangoDB web interface and navigate to `SERVICES`.
- Then click `Add Service`. Select `New Service` and fill out all fields with `*`.
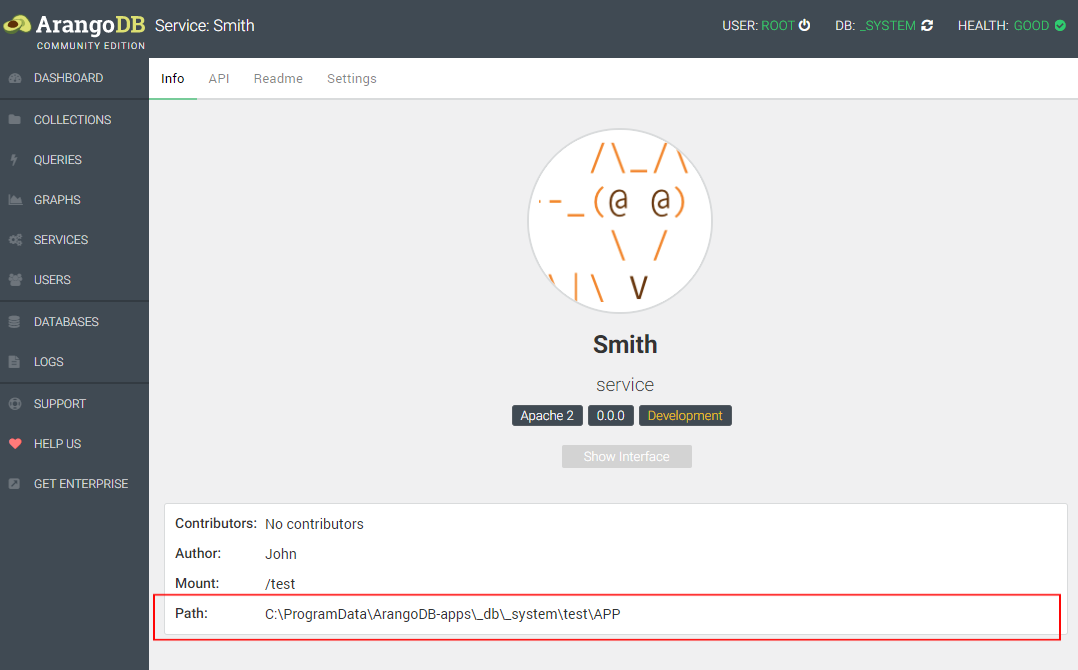
Important is the `Mount` field. I will use `/test`. Then Generate. - Click on the service to open its settings. Click `Settings` and then go to `Set Development` to enable the development mode.
- Then click `Info` and open the path at `Path:`.
Now we have to install the npm package:
npm install --save graphql-aql-generatorWe also need the collections `Author` and `BlogEntry`. And the following documents:
- `Author` collection:
{
"_key":"2"
"name": "Author Name"
}- `BlogEntry` collection:
{
"_key":"1"
"authorKey": "2"
}Foxx has a built-in graphql router that we can use to serve GraphQL queries. We assemble a new route called `/graphql` that serves the incoming GraphQL queries. With `graphiql: true` we enable the GraphiQL explorer so we can test-drive our queries.
const createGraphQLRouter = require('@arangodb/foxx/graphql');
const generator = require('graphql-aql-generator');
const typeDefs = [`...`]
const schema = generator(typeDefs);
router.use('/graphql', createGraphQLRouter({
schema: schema,
graphiql: true,
graphql: require('graphql-sync')
}));Open `127.0.0.1:8529/test/graphql` and the GraphiQL explorer is loaded so we can execute a query to fetch a `BlogEntry` with an `Author`.
{
blogEntry(_key: "1") {
_key
authorKey
author {
name
}
}
}
```
The result is:
```
{
"data": {
"blogEntry": {
"_key": "1",
"authorKey": "2",
"author": {
"name": "Author Name"
}
}
}
}For the sake of completeness, here is the full Foxx example that works by copy & paste. Do not forget to
`npm install graphql-aql-generator` and create the collections and documents.
// main.js code
'use strict';
const createRouter = require('@arangodb/foxx/router');
const router = createRouter();
module.context.use(router);
const createGraphQLRouter = require('@arangodb/foxx/graphql');
const generator = require('graphql-aql-generator');
const typeDefs = [`
type BlogEntry {
_key: String!
authorKey: String!
author: Author @aql(exec: "FOR author in Author filter author._key == @current.authorKey return author")
}
type Author {
_key: String!
name: String
}
type Query {
blogEntry(_key: String!): BlogEntry
}
`]
const schema = generator(typeDefs);
router.use('/graphql', createGraphQLRouter({
schema: schema,
graphiql: true,
graphql: require('graphql-sync')
}));Would be great to hear your thoughts, feedback, questions, and comments in our Slack Community channel or via a contact us form.
ArangoDB | Geo Demonstration Using Foxx – Location-Aware Applications
Geo data is getting more and more important for today’s applications. The growing number of location-aware services, IoT applications and other solutions using latitude and longitude ask for precise and fast processing of geo data.
Let me show you in this quick demonstration how you can use geo functions and visualize your data using Foxx and leaflet.js. Read more
ArangoDB | Pronto Move Shard – Multi-Model NoSQL Database
In July Adobe announced that they plan the End-of-Life for flash at around 2020.
As HTML5 progressed and due to a long history of critical security vulnerabilities this is – technologically speaking – certainly the right decision. However I tended to also become a bit sad.
Flash was the first technology that brought interactivity to the web. We tend to forget how static the web was in the early 2000s. Flash brought life to the web and there were plenty of stupid trash games and animations which I really enjoyed at the time. As a homage to the age of trashy flash games I created a game which resembles the games of this era: Read more
ArangoDB 3.2: RocksDB, Pregel, Fault Tolerant Foxx, Satellite Collections
We are pleased to announce the release of ArangoDB 3.2. Get it here. After an unusually long hackathon, we eliminated two large roadblocks, added a long overdue feature and integrated an interesting new one into this release. Furthermore, we’re proud to report that we increased performance of ArangoDB on average by 35%, while at the same time reduced the memory footprint compared to version 3.1. In combination with a greatly improved cluster management, we think ArangoDB 3.2 is by far our best work. (see release notes for more details)
One key goal of ArangoDB has always been to provide a rock solid platform for building ideas. Our users should always feel safe to try new things with minimal effort by relying on ArangoDB. Todays 3.2 release is an important milestone towards this goal. We’re excited to release such an outstanding product today.
RocksDB
![]() With the integration of Facebook's RocksDB, as a first pluggable storage engine in our architecture, users can now work with as much data as fits on disk. Together with the better locking behavior of RocksDB (i.e., document-level locks), write intensive applications will see significant performance improvements. With no memory limit and only document-level locks, we have eliminated two roadblocks for many users. If one chooses RocksDB as the storage engine, everything, including indexes will persist on disk. This will significantly reduce start-up time.
With the integration of Facebook's RocksDB, as a first pluggable storage engine in our architecture, users can now work with as much data as fits on disk. Together with the better locking behavior of RocksDB (i.e., document-level locks), write intensive applications will see significant performance improvements. With no memory limit and only document-level locks, we have eliminated two roadblocks for many users. If one chooses RocksDB as the storage engine, everything, including indexes will persist on disk. This will significantly reduce start-up time.
See this how-to on “Comparing new RocksDB and mmfiles engine” to test the new engine for your operating system and use case.
Pregel
Distributed graph processing was a missing feature in ArangoDB’s graph toolbox. We’re willing to admit that, especially since we managed to fill this need by implementing the Pregel computing model.
With PageRank, Community Detection, Vertex Centrality Measures and further algorithms, ArangoDB can now be used to gain high-level insights into the hidden characteristics of graphs. For instance, you can use graph processing capabilities to detect communities. You can then use the results to shard your data efficiently to a cluster and thereby enable SmartGraph usage to its full potential. We’re confident that with the integration of distributed graph processing, users will now have one of the most complete graph toolsets available in a single database.
Test the new pregel integration with this Community Detection Tutorial and further sharpen advanced graph skills with this new tutorial about Using SmartGraphs in ArangoDB.
Fault-Tolerant Foxx Services
Many people already enjoy using our Foxx JavaScript framework for data-centric microservices. Defining your own highly configurable HTTP routes with full access to the ArangoDB core on the C++ level can be pretty handy. In version 3.2, our Foxx team completely rewrote the management internals to support fault-tolerant Foxx services. This ensures multi-coordinator clusters will always keep their services in sync, and new coordinators are fully initialized, even when all existing coordinators are unavailable.
Test the new fault-tolerant Foxx yourself or learn Foxx by following the brand new Foxx tutorial.
Powerful Graph Visualization
Managing and processing graph data may not be enough, causing visualizing insights to be important. No worries. With ArangoDB 3.2, this can be handled easily. You can use the open-source option via arangoexport to export the data and then import it into Cytoscape (check out the tutorial).

Or you can just plug in the brand new Keylines 3.5 via Foxx and install an on-demand connection. With this option, you will always have the latest data visualized neatly in Keylines without any export/import hassle. Just follow this tutorial to get started with ArangoDB and Keylines.

Read-Only Users
To enhance basic user management in ArangoDB, we added Read-Only Users. The rights of these users can be defined on database and collection levels. On the database level, users can be given administrator rights, read access or denied access. On the collection level, within a database, users can be given read/write, read only or denied access. If a user is not given access to a database or a collection, the databases and collections won’t be shown to that user. Take the tutorial about new User Management.
We also improved geo queries since this is becoming more important to our community. With geo_cursor, it’s now possible to sort documents by distance to a certain point in space (Take the tutorial). This makes queries simple like, “Where can I eat vegan in a radius of one mile around Times Square?” We plan to add support for other geo-spatial functions (e.g., polygons, multi-polygons) in the next minor release. So watch for that.
ArangoDB 3.2 Enterprise Edition: More Room for Secure Growth
The Enterprise Edition of ArangoDB is focused on solving enterprise-scale problems and secure work with data. In version 3.1, we introduced SmartGraphs to bring fast traversal response times to sharded datasets in a cluster. We also added auditing and enhanced encryption control. Download ArangoDB Enterprise Edition (forever free evaluation).
Working closely with one of our larger clients, we further explored and improved an idea we had about a year ago. Satellite Collections is the exciting result of this collaboration. It’s designed to enable faster join operations when working with sharded datasets. To avoid expensive network hops during join processing among machines, one has ‘only’ to find a solution to enable joins locally.
With Satellite Collections, you can define collections to shard to a cluster, as well as set collections to replicate to each machine. The ArangoDB query optimizer knows where each shard is located and sends requests to the DBServers involved, which then execute the query locally. The DBservers will then send the partial results back to the Coordinator which puts together the final result. With this approach, network hops during join operations on sharded collections can be avoided, hence query performance is increased and network traffic reduced. This can be more easily understood with an example. In the schema below, collection C is sharded to multiple machines, while the smaller satellites (i.e., S1 - S5) are replicated to each machine, orbiting the shards of C.

Use cases for Satellite Collection are plentiful. In this more in-depth blog post, we use the example of an IoT case. Personalized patient treatment based on genome sequencing analytics is another excellent example where efficient join operations involving large datasets, can help improve patient care and save infrastructure costs.
Security Enhancements
From the very beginning of ArangoDB, we have been concerned with security. AQL is already protected from injections. By using Foxx, sensitive data can be contained within in a database, with only the results being passed to other systems, thus minimizing security exposure. But this is not always enough to meet enterprise scale-security requirements. With version 3.1, we introduced Auditing and Enhanced Encryption Control and with ArangoDB 3.2, we added even more protection to safeguard data.
Encryption at Rest
With RocksDB, you can encrypt the data stored on disk using a highly secure AES algorithm. Even if someone steals one of your disks, they won’t be able to access the data. With this upgrade, ArangoDB takes another big step towards HIPAA compliance.
Enhanced Authentication with LDAP
Normally, users are defined and managed in ArangoDB itself. With LDAP, you can use an external server to manage your users. We have implemented a common schema which can be extended. If you have special requirements that don’t fit into this schema, please let us know.
Conclusion & You
The entire ArangoDB team is proud to release version 3.2 of ArangoDB -- this should not be a surprise considering all of the improvements we made. We hope you will enjoy the upgrade. We invite you to take ArangoDB 3.2 for a spin and to let us know what you think. We look forward to your feedback!
Download ArangoDB 3.2
ArangoDB 3.2: Enhanced GraphQL Sync
Just in time for the upcoming 3.2.0 release, we have updated the graphql-sync module for compatibility with graphql-js versions 0.7.2, 0.8.2, 0.9.6 and 0.10.1. The graphql-sync module allows developers to implement GraphQL backends and schemas in strictly synchronous JavaScript environments like the ArangoDB Foxx framework by providing a thin wrapper around the official GraphQL implementation for JavaScript.
As a long-term database solution, ArangoDB is committed to API stability and avoids upgrades to third-party dependencies that would result in breaking changes. This means ArangoDB will continue to bundle the graphql-js 0.6.2 compatibility version of graphql-sync.
ArangoDB 3.2 Beta: RocksDB Storage Engine & Distributed Graph Cluster
We’re excited to release today the beta of ArangoDB 3.2. It’s feature rich, well tested and hopefully plenty of fun for all of you. Keen to take it for a spin? Get ArangoDB 3.2 beta here.
With ArangoDB 3.2, we’re introducing the long-awaited pluggable storage engine and its first new citizen, RocksDB from Facebook
- RocksDB: You can now use as much data in ArangoDB as you can fit on your disk. Plus, you can enjoy performance boosts on writes by having only document-level locks (more info below).
- Pregel: Furthermore, we implemented distributed graph processing with Pregel for discovering hidden patterns, identify communities and perform in-depth analytics of large graph data sets.
- ClusterFoxx: Another important upgrade is what we internally and playfully call the ClusterFoxx. The Foxx management internals have been rewritten from the ground up to make sure multi-coordinator cluster setups always keep their services in sync and new coordinators are fully initialised even when all existing coordinators are unavailable.
- Enterprise: Working with some of our largest customers, we’ve added further security and scalability features to ArangoDB Enterprise like LDAP integration, Encryption at Rest, and the brand new Satellite Collections.
The goal of the whole ArangoDB 3 release cycle has been to scale the multi-model idea to new heights. Getting ‘ready’ for large scale applications is not done overnight and it’s definitely not possible without the help of a strong community. We’d like to invite all of you to lend us a helping hand to make ArangoDB 3.2 the best release ever. Please push this beta to its limits: test it for your use cases and compare the performance of the new features like RocksDB. Let us know on Github any bug that you find. Don’t worry about hurting our feelings: we want to fix any problems.
Join the Beta Bug Hunt Challenge and win a $200 Amazon Gift Card as first prize. You can find more details about this reward program at the end of this post.
New Storage Engine RocksDB
![]() ArangoDB now comes with two storage engines: mmfiles and RocksDB. If you want to compare the engines, you can use arangodump to export data from either engine and arangorestore to import into the other. MMFILES are generally well suited for use-cases that fit into main memory, while RocksDB allows larger than memory work-sets.
ArangoDB now comes with two storage engines: mmfiles and RocksDB. If you want to compare the engines, you can use arangodump to export data from either engine and arangorestore to import into the other. MMFILES are generally well suited for use-cases that fit into main memory, while RocksDB allows larger than memory work-sets.
RocksDB has plenty of configuration options; we have selected the general purpose options. Please let us know how it works for your use case so that we can further optimize the implementation. Also notice that we do many tests under Linux, Windows and macOS. However, we optimize for Linux. Any feedback regarding other operating systems is very welcome. Check out the step by step guide to compare both storage engines for your use case and OS!
Benefits of RocksDB Storage Engine:
- Document-level locks: performance boost for write intensive applications. Writes don’t block reads, and reads don’t block writes
- Support for large datasets: go beyond the limit of main memory and stay performant
- Persistent indexes: faster index build after restart
Things to consider before switching to RocksDB
- RocksDB allows concurrent writes: Write conflicts can be raised. Applications switching from MMFiles must be prepared for exceptions
- Transaction Limit in RocksDB: The total size of transactions is limited in RocksDB. Modifying statements on large amounts of documents have to commit in between -- with AQL this is done by default.
- Engine Selection on Server/Cluster Level: It’s not possible to mix both storage engines within a single instance or cluster installation. Transaction handling and write ahead log formats are different.
Find all important details about RocksDB in the storage engine documentation, as well as answers to common questions about our RocksDB integration in the FAQ.
Please note that ArangoDB 3.2 beta is fully tested, but not yet fully optimized (known-issues RocksDB). If you find something that is much slower with RocksDB compared to your current queries with the MMFiles engine, please create a github ticket. Please check the comparison guide here.
New Distributed Graph Processing
With the new implementation of distributed graph processing, you are now able to analyze even very large graph data sets as a whole. Internally, we implemented the pregel computing model to enable ArangoDB to support arbitrary graph algorithms, which will scale with your data -- or with the size of your database cluster.

You can already use a number of well-known graph algorithms:
- PageRank
- Weakly Connected Components
- Strongly Connected Components
- HITS (hubs and authorities)
- Single-Source Shortest Path
- Community Detection via Label Propagation
- Vertex Centrality measures
- Closeness Centrality via Effective Closeness
- Betweenness Centrality via LineRank
By using these new capabilities, you are now able, for example, to detect communities within your graph, shard your data according to these communities and leverage ArangoDB SmartGraphs to perform highly efficient graph traversals even in a cluster setup.
New ClusterFoxx
![]() Managing your JavaScript microservices is now easier and more reliable than ever before. The Foxx management internals have been rewritten to make sure multi-coordinator cluster setups always keep their services in sync and new coordinators are fully initialised even when all existing coordinators are unavailable.
Managing your JavaScript microservices is now easier and more reliable than ever before. The Foxx management internals have been rewritten to make sure multi-coordinator cluster setups always keep their services in sync and new coordinators are fully initialised even when all existing coordinators are unavailable.
Additionally, the new fully documented REST API for managing Foxx services enables you to install, upgrade and configure your services using your existing devops processes. And if your service only consists of a single JavaScript file, you can now forego the manifest and upload that file directly, instead of creating a full bundle.
Further useful new features included in ArangoDB 3.2 beta
- geo_cursor: Get documents sorted by distance to a certain point in space. You can also apply filters and limits to geo_cursor.
- arangoexport: Export data as JSON, JSONL and even graphs as XGMML for visualisation in Cytoscape. You can find details in the Alpha2 release post.
Download ArangoDB 3.2 beta Community
New Enterprise Edition Features in 3.2
![]() The Enterprise Edition of ArangoDB is focused to solve enterprise-scale problems and meet high security standards. In version 3.1, we introduced SmartGraphs to bring fast traversal times to sharded graph datasets. With SatelliteCollections, we enable the same performance boost to join operations at scale.
The Enterprise Edition of ArangoDB is focused to solve enterprise-scale problems and meet high security standards. In version 3.1, we introduced SmartGraphs to bring fast traversal times to sharded graph datasets. With SatelliteCollections, we enable the same performance boost to join operations at scale.
SatelliteCollections
From genome-sequencing projects to massive online games and beyond, we see the need for join operations including sharded collections and sub-second response times.
With SatelliteCollections, you can define collections to shard to a cluster and collections to replicate to each machine. The ArangoDB query optimizer knows where each shard is located and sends the requests to the DBServers involved, which then executes the query, locally. With this approach, network hops during join operations on sharded collections can be avoided and response times can be close to that of a single instance.
In the example below, collection C is large and sharded to multiple machines while the smaller satellites (S1-S5) are replicated to each machine.

We are super excited to see what you will create with this new feature and welcome any feedback you can provide. The Enterprise Edition of ArangoDB is forever free for evaluation. So feel free to take it for a spin.
Encryption at Rest
With RocksDB, you can encrypt the data stored on disk using a highly secure AES algorithm. With this upgrade, ArangoDB takes another big step towards HIPPA compliance. Even if someone steals one of your discs, they won’t be able to access the data.
Enhanced Authorisation with LDAP
Normally, users are defined and managed in ArangoDB itself. With LDAP, you can use an external server to manage your users. We have implemented a common schema which can be extended. If you have special requirements that do not fit into this schema, please let us know (#feedback32 channel). A general note: The final release will also support read-only users. With this beta, only read/write users are supported.
Download ArangoDB 3.2 beta Enterprise
Bug Hunt Competition
We’d love to invite all of you to try ArangoDB 3.2 beta and report all bugs you can find -- we’re hoping there won’t be any, but there always are some. Everyone reporting bugs for 3.2 beta on Github will take part in the Beta Bug Hunt Competition. All Github issues count for version 3.2 beta which are marked with bug by the ArangoDB team. The hunter with the most reported bugs wins. The first three runner-ups will receive an honorable mention in the Bug Hunt Challenge post.
How the Bug Hunt Competition works:
- Duration: from June 13th until June 27th
- Bugs: Any Github issue for 3.2 beta release which is marked as bug by ArangoDB team
- Who can participate: everyone
- First Prize: a $200 Amazon Gift Card + ArangoDB Swag Package
- Second Prize: $100 Amazon Gift Card + ArangoDB Swag Package
- Runner-Up: ArangoDB Swag Package
All winners will receive an honorable mention in the bug hunt post and tweets after the challenge. Please note that our team has to be able to reproduce the bug.
Therefore good bug reports
- Have only necessary infos included
- Provide a step by step description to reproduce the bug
- Provide demo data via e.g. gist (if necessary)
We hope you will enjoy this new release - “Gute Jagd!”
Legal
In connection with your participation in this program you agree to comply with all applicable local and national laws. You must not disrupt or compromise any data that is not your own.
ArangoDB reserves the right to discontinue this program or change or modify its terms at any time. The ultimate decision over an award -- whether to give one and in what amount -- is entirely at ArangoDB’s discretion.
You are exclusively responsible for paying any taxes on any reward you receive.
Vulnerabilities obtained by exploiting ArangoDB users or instances on the Internet are not eligible for an award and will result in immediate disqualification from the program.
ArangoDB FoxxChallenge: Developer Competition
The Challenge
![]() Starting today we launch the ArangoDB #FoxxChallenge and the winner will receive a brand new Amazon Echo.
Starting today we launch the ArangoDB #FoxxChallenge and the winner will receive a brand new Amazon Echo.
Use your knowledge about everyday needs in projects and create a Foxx service that could be helpful for others. If you need some inspiration here some ideas: Read more
How to model customer surveys in a graph database
Use-Case
The graph database use-case we are stepping through in this post is the following: In our web application we have several places where a user is led through a survey, where she decides on details for one of our products. Some of the options within the survey depend on previous decisions and some are independent.
Examples:
- Configure a new car
- Configure a new laptop
- Book extras with your flight (meal, reserve seat etc.)
- Configure a new complete kitchen
- Collect customer feedback via logic-jump surveys
Using GraphQL with ArangoDB: A NoSQL Database Solution
GraphQL is a query language created by Facebook for modern web and mobile applications as an alternative to REST APIs. Following the original announcement alongside Relay, Facebook has published an official specification and reference implementation in JavaScript. Recently projects outside Facebook like Meteor have also begun to embrace GraphQL.
Users have been asking us how they can try out GraphQL with ArangoDB. While working on the 2.8 release of our NoSQL database we experimented with GraphQL and published an ArangoDB-compatible wrapper for GraphQL.js. With the general availability of ArangoDB 2.8 you can now use GraphQL in ArangoDB using Foxx services (JavaScript in the database).
A GraphQL primer
GraphQL is a query language that bears some superficial similarities with JSON. Generally GraphQL APIs consist of three parts:
The GraphQL schema is implemented on the server using a library like graphql-sync and defines the types supported by the API, the names of fields that can be queried and the types of queries that can be made. Additionally it defines how the fields are resolved to values using a backend (which can be anything from a simple function call, a remote web service or accessing a database collection).
The client sends queries to the GraphQL API using the GraphQL query language. For web applications and JavaScript mobile apps you can use either GraphQL.js or graphql-sync to make it easier to generate these queries by escaping parameters.
The server exposes the GraphQL API (e.g. using an HTTP endpoint) and passes the schema and query to the GraphQL implementation, which validates and executes the query, later returning the output as JSON.
GraphQL vs REST
Whereas in REST APIs each endpoint represents a single resource or collection of resources, GraphQL is agnostic of the underlying protocols. When used via HTTP it only needs a single endpoint that handles all queries.
The API developer still needs to decide what information should be exposed to the client or what access controls should apply to the data but instead of implementing them at each API endpoint, GraphQL allows centralising them in the GraphQL schema. Instead of querying multiple endpoints, the client can pick and choose from the schema when defining the query and filter the response to only contain the fields it actually needs.
For example, the following GraphQL query:
query {
user(id: "1234") {
name
friends {
name
}
}
}
could return a response like this:
{
"data": {
"user": {
"name": "Bob",
"friends": [
{
"name": "Alice"
},
{
"name": "Carol"
}
]
}
}
}
whereas in a traditional REST API accessing the names of the friends would likely require additional API calls and filtering the responses to certain fields would either require proprietary extensions or additional endpoints.
GraphQL Demo Service
If you are running ArangoDB 2.8 you can install the Foxx service demo-graphql from the Store. The service provides a single HTTP POST endpoint /graphql that accepts well-formed GraphQL queries against the Star Wars data set used by GraphQL.js.
It supports three queries:
hero(episode)returns thehumanordroidthat was the hero of the given episode or the hero of the Star Wars saga if no episode is specified. The valid IDs of the episodes are"NewHope","Empire","Jedi"and"Awakens"corresponding to episodes 4, 5, 6 and 7.human(id)returns the human with the given ID (a string value in the range of"1000"to"1007"). Humans have anid,nameand optionally ahomePlanet.droid(id)does the same for droids (with IDs"2000","2001"and"2002"). Droids don't have ahomePlanetbut may have aprimaryFunction.
Both droids and humans have friends (which again can be humans or droids) and a field appearsIn mapping them to episodes (which have an id, title and description).
For example, the following query:
{
human(id: "1007") {
name
friends {
name
}
appearsIn {
title
}
}
}
returns the following JSON:
{
"data": {
"human": {
"name": "Wilhuff Tarkin",
"friends": [
{
"name": "Darth Vader"
}
],
"appearsIn": [
{
"title": "A New Hope"
}
]
}
}
}
It's also possible to do deeply nested lookups like "what episodes have the friends of friends of Luke Skywalker appeared in" (but note that mutual friendships will result in some duplication in the output):
{
human(id: "1000") {
friends {
friends {
appearsIn {
title
}
}
}
}
}
Additionally it's possible to make queries about the API itself using __schema and __type. For example, the following tells us the "droid" query returns something of a type called "Droid":
{
__schema {
queryType {
fields {
name
type {
name
}
}
}
}
}
And the next query tells us what fields droids have (so we know what fields we can request when querying droids):
{
__type(name: "Droid") {
fields {
name
}
}
}
GraphQL: The Good
GraphQL shifts the burden of having to specify what particular subset of information should be returned to the client. Unlike traditional REST based solutions this is built into the language from the start: a client will only see information they explicitly request, they don't have to know about anything they're not already interested in.
At the same time a single GraphQL schema can be written to represent the entire global state graph of an application domain without having to hard-code any assumptions about how that data will be presented to the user. By making the schema declarative GraphQL avoids the necessary duplication and potential for subtle bugs involved in building equally exhaustive HTTP APIs.
GraphQL also provides mechanisms for introspection, allowing developers to explore GraphQL APIs without external documentation.
GraphQL is also protocol agnostic. While REST directly builds on the semantics of the underlying HTTP protocol, GraphQL brings its own semantics, making it easy to re-use GraphQL APIs for non-HTTP communication (such as Web Sockets) with minimal effort.
GraphQL: The Bad
The main drawback of GraphQL as implemented in GraphQL.js is that each object has to be retrieved from the data source before it can be queried further. For example, in order to retrieve the friends of a person, the schema has to first retrieve the person and then retrieve the person's friends using a second query.
Currently all existing demonstrations of GraphQL use external databases with ORMs or ODMs with complex GraphQL queries causing multiple consequent network requests to an external database. This added cost of network latency, transport overhead, serialization and deserialization makes using GraphQL slow and inefficient compared to an equivalent API using hand-optimized database queries.
This can be mitigated by inspecting the GraphQL Abstract Syntax Tree to determine what fields will be accessed on the retrieved document. However, it doesn't seem feasible to generate efficient database queries ad hoc, foregoing a lot of the optimizations otherwise possible with handwritten queries in databases.
Conclusion
Although there doesn't seem to be any feasible way to translate GraphQL requests into database-specific queries (such as AQL), the impact of having a single GraphQL request result in a potentially large number of database requests is much less significant when implementing the GraphQL backend directly inside the database.
While RESTful HTTP APIs are certainly here to stay and GraphQL like any technology has its own trade-offs, the advantages of having a standardized yet flexible interface for accessing and manipulating an application's global state graph are undeniable.
GraphQL is a promising fit for schema-free databases and dynamically typed languages. Instead of having to spread validation and authorization logic across different HTTP endpoints and native database format restrictions a GraphQL schema can describe these concerns. Thus guaranteeing that sensitive fields are not accidentally exposed and the data formats remain consistent across different queries.
We're excited to see what the future will hold for GraphQL and encourage you to try out GraphQL in the database with ArangoDB 2.8 and Foxx today. Have a look at the demo-graphql from the Store. If you have built or are planning to build applications using GraphQL and ArangoDB, let us know in the comments.