 Skip to content
Skip to content Setting up Datacenter to Datacenter Replication in ArangoDB
Please note that this tutorial is valid for the ArangoDB 3.3 milestone 1 version of DC to DC replication!
Interested in trying out ArangoDB? Fire up your cluster in just a few clicks with ArangoDB ArangoGraph: the Cloud Service for ArangoDB. Start your free 14-day trial here
This milestone release contains data-center to data-center replication as an enterprise feature. This is a preview of the upcoming 3.3 release and is not considered production-ready.
In order to prepare for a major disaster, you can setup a backup data center that will take over operations if the primary data center goes down. For a server failure, the resilience features of ArangoDB can be used. Data center to data center is used to handle the failure of a complete data center.
Data is transported between data-centers using a message queue. The current implementation uses Apache Kafka as message queue. Apache Kafka is a commonly used open source message queue which is capable of handling multiple data-centers. However, the ArangoDB replication is not tied to Apache Kafka. We plan to support different message queues systems in the future.
The following contains a high-level description how to setup data-center to data-center replication. Detailed instructions for specific operating systems will follow shortly. Read more
Auto-Generate GraphQL for ArangoDB
Currently, querying ArangoDB with GraphQL requires building a GraphQL.js schema. This is tedious and the resulting JavaScript schema file can be long and bulky. Here we will demonstrate a short proof of concept that reduces the user related part to only defining the GraphQL IDL file and simple AQL queries.
The Apollo GraphQL project built a library that takes a GraphQL IDL and resolver functions to build a GraphQL.js schema. Resolve functions are called by GraphQL to get the actual data from the database. I modified the library in the way that before the resolvers are added, I read the IDL AST and create resolver functions.
To simplify things and to not depend on special "magic", let's introduce the directive `@aql`. With this directive, it's possible to write an AQL query that gets the needed data. With the bind parameter `@current` it is possible to access the current parent object to do JOINs or related operations.
Interested in trying out ArangoDB? Fire up your database in just a few clicks with ArangoDB ArangoGraph: the Cloud Service for ArangoDB. Start your free 14-day trial here.
A GraphQL IDL
type BlogEntry {
_key: String!
authorKey: String!
author: Author @aql(exec: "FOR author IN Author FILTER author._key == @current.authorKey RETURN author")
}
type Author {
_key: String!
name: String
}
type Query {
blogEntry(_key: String!): BlogEntry
}This IDL describes a `BlogEntry` and an `Author` object. The `BlogEntry` holds an `Author` object which is fetched via the AQL query in the directive `@aql`. The type Query defines a query that fetches one `BlogEntry`.
Now let's have a look at a GraphQL query:
{
blogEntry(_key: "1") {
_key
authorKey
author {
name
}
}
}This query fetches the `BlogEntry` with `_key` "1". The generated AQL query is:
FOR doc IN BlogEntry FILTER doc._key == '1' RETURN docAnd with the fetched `BlogEntry` document the corresponding `Author` is fetched via the AQL query defined in the directive.
The result will approximately look like this:
{
"data" : {
"blogEntry" : {
"_key" : "1",
"authorKey" : "2",
"author" : {
"name" : "Author Name"
}
}
}
}As a conclusion of this short demo, we can claim that with the usage of GraphQLs IDL, it is possible to reduce effort on the users' side to query ArangoDB with GraphQL. For simple GraphQL queries and IDLs it's possible to automatically generate resolvers to fetch the necessary data.
The effort resulted in an npm package is called graphql-aql-generator.
ArangoDB Foxx example
Now let’s have a look at the same example, but with using ArangoDB javascript framework - Foxx. To do so, we have to follow the simple steps listed below:
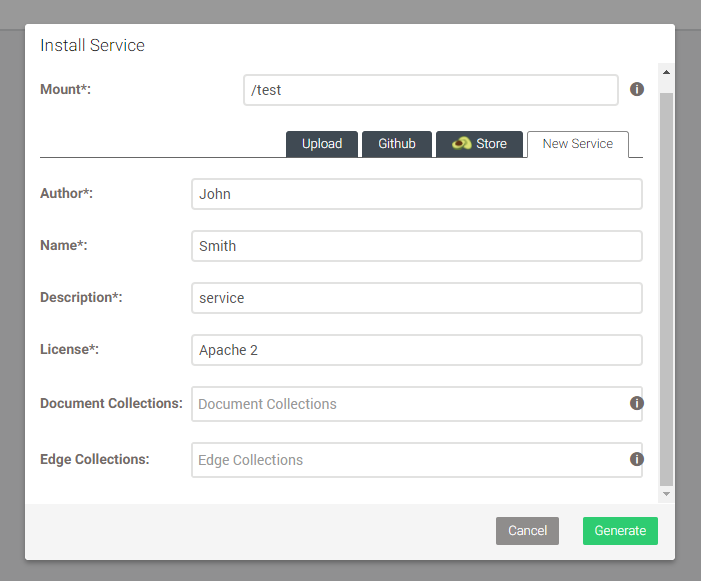
- Open the ArangoDB web interface and navigate to `SERVICES`.
- Then click `Add Service`. Select `New Service` and fill out all fields with `*`.
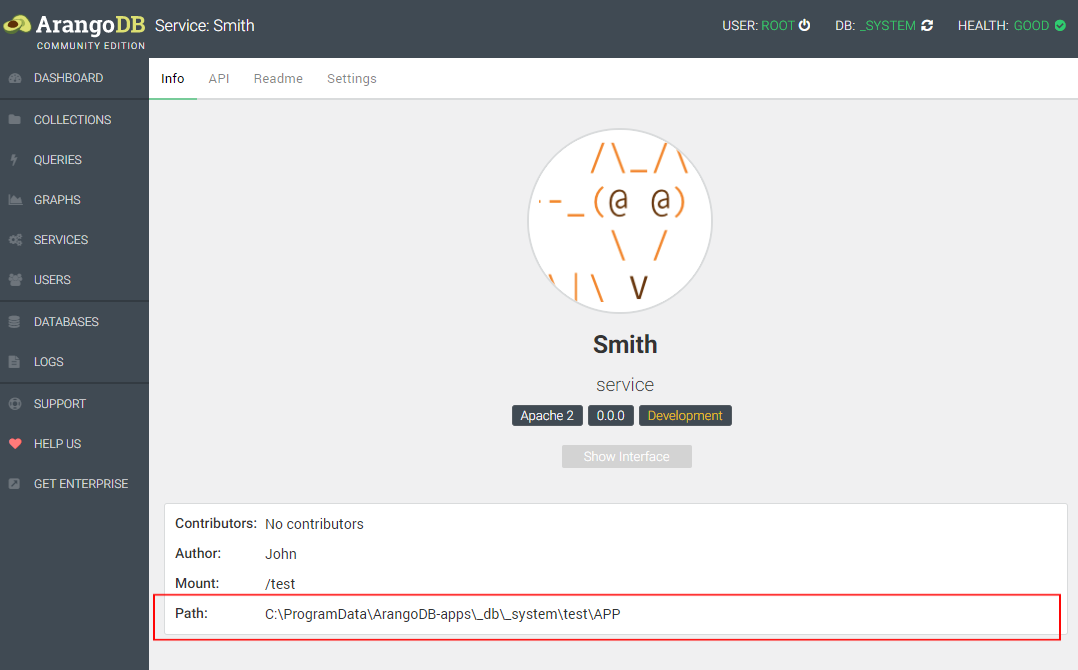
Important is the `Mount` field. I will use `/test`. Then Generate. - Click on the service to open its settings. Click `Settings` and then go to `Set Development` to enable the development mode.
- Then click `Info` and open the path at `Path:`.
Now we have to install the npm package:
npm install --save graphql-aql-generatorWe also need the collections `Author` and `BlogEntry`. And the following documents:
- `Author` collection:
{
"_key":"2"
"name": "Author Name"
}- `BlogEntry` collection:
{
"_key":"1"
"authorKey": "2"
}Foxx has a built-in graphql router that we can use to serve GraphQL queries. We assemble a new route called `/graphql` that serves the incoming GraphQL queries. With `graphiql: true` we enable the GraphiQL explorer so we can test-drive our queries.
const createGraphQLRouter = require('@arangodb/foxx/graphql');
const generator = require('graphql-aql-generator');
const typeDefs = [`...`]
const schema = generator(typeDefs);
router.use('/graphql', createGraphQLRouter({
schema: schema,
graphiql: true,
graphql: require('graphql-sync')
}));Open `127.0.0.1:8529/test/graphql` and the GraphiQL explorer is loaded so we can execute a query to fetch a `BlogEntry` with an `Author`.
{
blogEntry(_key: "1") {
_key
authorKey
author {
name
}
}
}
```
The result is:
```
{
"data": {
"blogEntry": {
"_key": "1",
"authorKey": "2",
"author": {
"name": "Author Name"
}
}
}
}For the sake of completeness, here is the full Foxx example that works by copy & paste. Do not forget to
`npm install graphql-aql-generator` and create the collections and documents.
// main.js code
'use strict';
const createRouter = require('@arangodb/foxx/router');
const router = createRouter();
module.context.use(router);
const createGraphQLRouter = require('@arangodb/foxx/graphql');
const generator = require('graphql-aql-generator');
const typeDefs = [`
type BlogEntry {
_key: String!
authorKey: String!
author: Author @aql(exec: "FOR author in Author filter author._key == @current.authorKey return author")
}
type Author {
_key: String!
name: String
}
type Query {
blogEntry(_key: String!): BlogEntry
}
`]
const schema = generator(typeDefs);
router.use('/graphql', createGraphQLRouter({
schema: schema,
graphiql: true,
graphql: require('graphql-sync')
}));Would be great to hear your thoughts, feedback, questions, and comments in our Slack Community channel or via a contact us form.
ArangoDB | PyArango Performance Analysis – Transaction Inspection
Following the previous blog post on performance analysis with pyArango, where we had a look at graphing using statsd for simple queries, we will now dig deeper into inspecting transactions. At first, we split the initialization code and the test code.
Initialisation code
We load the collection with simple documents. We create an index on one of the two attributes: Read more
Performance analysis using pyArango Part I
This is Part I of Performance analysis using pyArango blog series. Please refer here for: Part II (cluster) and Part III (measuring system capacity).
Usually, your application will persist of a set of queries on ArangoDB for one scenario (i.e. displaying your user’s account information etc.) When you want to make your application scale, you’d fire requests on it, and see how it behaves. Depending on internal processes execution times of these scenarios vary a bit.
We will take intervals of 10 seconds, and graph the values we will get there:
- average – all times measured during the interval, divided by the count.
- minimum – fastest requests
- maximum – slowest requests
- the time “most” aka 95% of your users may expect an answer within – this is called 95% percentile
ArangoDB | Geo Demonstration Using Foxx – Location-Aware Applications
Geo data is getting more and more important for today’s applications. The growing number of location-aware services, IoT applications and other solutions using latitude and longitude ask for precise and fast processing of geo data.
Let me show you in this quick demonstration how you can use geo functions and visualize your data using Foxx and leaflet.js. Read more
Sorting number strings numerically
Recently I gave a talk about ArangoDB in front of a community of mathematicians. I advertised that nearly arbitrary data can “easily” be stored in a JSON based document store. The moment I had uttered the word “easily”, one of them asked about long integers. And if a mathematician says “long integer” they do not mean 64bit but “properly long”. He actually wanted to store orders of finite groups. I said one should use a JSON UTF-8 string for this but I should have seen the next question coming because he then wanted that a sorted index would actually sort the documents by the numerical value stored in the string. But most databases – and ArangoDB is no exception here – will compare UTF-8 strings lexicographically (dictionary order). Read more
Webinar: Use ArangoDB Agency as fault-tolerant persistent data store
Join our Sr Distributed System Engineer, Kaveh Vahedipour, to learn more about ArangoDB Agency on September 19th, 2017 (6PM CEST/12PM ET/ 9AM PT) – View the Recording.
Distributed systems have become the standard topology on which modern appliances live. While the advantages of distributing workload for both performance as well as fault-tolerance are obvious, the runtime flexible configuration of such deployment becomes non-trivial.
ArangoDB clusters are no different in that regard. A potentially large database cluster’s configuration is manipulated at runtime by addition, alteration and removal of collections, indexes, and even servers. All servers need to trust in a fault-tolerant centralized configuration tree, which we call “the agency” in arango-speak. Read more
ArangoDB | VelocyStream Async Binary Protocol – Data Streaming
With the 3.2 release, ArangoDB comes with version 1.1 of the binary protocol VelocyStream. VelocyStream is a bi-directional async binary protocol which supports sending messages pipelined, multiplexed, uni-directional or bi-directional. The messages themselves are VelocyPack objects. Read more
ArangoDB | Pronto Move Shard – Multi-Model NoSQL Database
In July Adobe announced that they plan the End-of-Life for flash at around 2020.
As HTML5 progressed and due to a long history of critical security vulnerabilities this is – technologically speaking – certainly the right decision. However I tended to also become a bit sad.
Flash was the first technology that brought interactivity to the web. We tend to forget how static the web was in the early 2000s. Flash brought life to the web and there were plenty of stupid trash games and animations which I really enjoyed at the time. As a homage to the age of trashy flash games I created a game which resembles the games of this era: Read more
ArangoDB Webinar: Apps with ArangoDB & KeyLines
Wednesday, September 6th (5PM CEST/11AM ET/8AM PT) – Join the webinar here
 As data gets bigger, faster and more complex, you need to arm yourself with the best tools. In this webinar we’ll see how KeyLines and ArangoDB combine to create powerful and intuitive data analysis platforms. Read more
As data gets bigger, faster and more complex, you need to arm yourself with the best tools. In this webinar we’ll see how KeyLines and ArangoDB combine to create powerful and intuitive data analysis platforms. Read more