 Skip to content
Skip to content 
Benchmark Results – ArangoDB vs. Neo4j : ArangoDB up to 8x faster than Neo4j
Introduction
This document presents the benchmark results comparing the ArangoDB’s Graph Analytics Engine (GAE) against Neo4j. The GAE is just one component of ArangoDB’s Data Science Suite.
This reproducible benchmark aims to provide a neutral and thorough comparison between the two databases, ensuring a fair and unbiased assessment.
We use the wiki-Talk dataset, a widely used, real-world graph dataset derived from the edit and discussion history of Wikipedia.
The wiki-Talk dataset encapsulates communication patterns between Wikipedia users, specifically interactions on user talk pages. This dataset is used frequently in benchmarking graph databases and graph analytics systems because of its unique characteristics. The key characteristics of wiki-Talk that make it a highly reliable benchmarking dataset are: Directed Graph, Nodes and Edges, Scale, Temporal Dimension, Sparsity, etc.
The results demonstrate the efficiency and scalability of each database, and offer a representative benchmark model for organizations evaluating graph databases for their needs.
Benchmark Highlights
The benchmark results reveal several notable insights, particularly highlighting ArangoDB's superior performance in graph analytics tasks compared to Neo4j. Most strikingly:
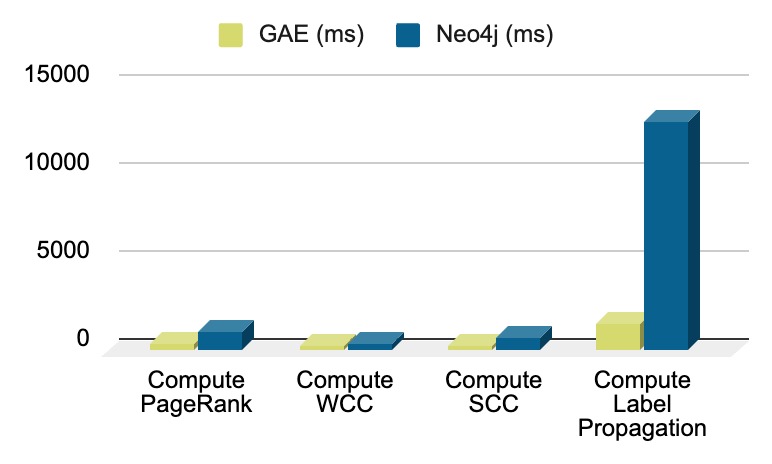
- ArangoDB consistently outperformed Neo4j across various graph computation algorithms, with performance improvements that range from 1.3 times to over 8 times faster.
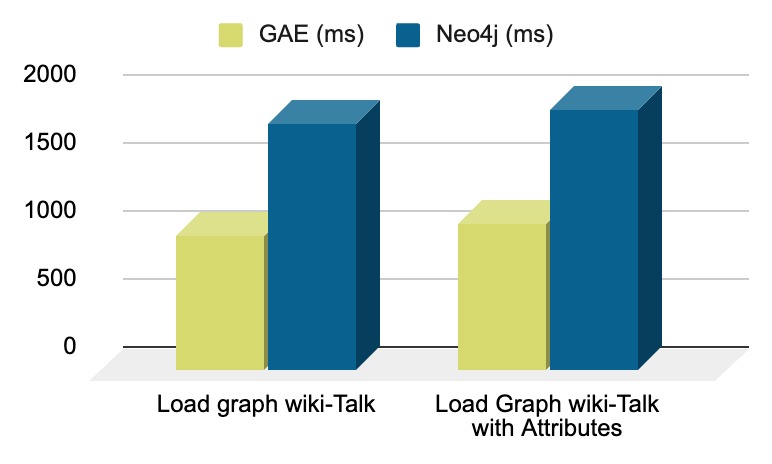
- This substantial speed advantage is also evident in graph loading times, where ArangoDB demonstrated an impressive 100% advantage in graph loading efficiency vs Neo4j, for the wiki-Talk dataset.
ArangoDB's optimized data storage and retrieval, combined with its advanced query execution and effective use of clustered deployments, also contributed significantly to its superior performance in these scenarios.
These findings underscore:
- ArangoDB's capability to handle much larger-scale and far faster real-time graph analytics applications.
- ArangoDB as a much more compelling choice for industries and organizations that require rapid data processing and analysis, such as real-time recommendation systems, social network analysis, fraud detection, and cyber security.
Benchmark Overview
Datasets (wiki-Talk)
We utilized the wiki-Talk dataset, a well-regarded dataset for evaluating graph database performance. The chosen graphs and their details are as follows:
| Graphs Used | Vertices | Edges |
|---|---|---|
| wiki-Talk | 2,394,385 | 5,021,410 |
Hardware
All tests were conducted on the same machine with the following specifications:
OS Ubuntu 23.10 (64-bit)
Memory 192 GB (4800 MHz)
CPU Ryzen 9 7950X3D (16 Cores, 32 Threads)
Database Configuration
***Neo4j***
Version 5.19.0 (Community Edition)
Deployment On-Premise, Single Process
***ArangoDB***
Version 3.12.0-NIGHTLY.20240305 (Community Edition)
Deployment On-Premise, Single Process
Graph Analytics Engine (GAE)
Version Latest
Deployment On-Premise, Single Process (RUST-based, no multithreading)
Benchmark Configuration
Two workflows were used to measure performance:
Workflow A:
- Create the in-memory representation
- Execute each algorithm once
- Measure the whole process
Workflow B
- Create the in-memory representation
- Measure graph creation time
- Execute each algorithm individually
- Measure computation time
Algorithms Tested
- Pagerank
- Weakly Connected Components (WCC)
- Strongly Connected Components (SCC)
- Label Propagation
Used Technologies
- JavaScript Framework: Vitest with tinybench
- Communication
- Neo4j: Official Neo4j JS driver ("neo4j-driver": "^5.18.0")
- GAE: Plain HTTPs requests using Axios ("axios": "^1.6.8")
Benchmark Results
Graph Loading (wiki-Talk)
| Task | GAE (sec) | Neo4j (sec) | Times Faster |
|---|---|---|---|
| Load graph wiki-Talk | 9.9 | 18 | 1.8 x |
| Load Graph wiki-Talk with Attributes | 10.7 | 19.2 | 1.8 x |
Graph Computation (wiki-Talk)
| Task | GAE (sec) | Neo4j (sec) | Times Faster |
|---|---|---|---|
| Compute PageRank | 3.8 | 10.6 | 2.8 x |
| Compute WCC | 2.3 | 4.5 | 1.7 x |
| Compute SCC | 3.2 | 6.7 | 2.1 x |
| Compute Label Propagation | 1.5 | 13 | 8.5 x |
Explanation of Elements
Graph Algorithms
- Pagerank, An algorithm that is used to rank nodes in a graph based on their connections, also commonly used in search engines.
- Weakly Connected Components (WCC), which identifies subsets of a graph where any two vertices are connected by paths, ignoring the direction of edges.
- Strongly Connected Components (SCC), Identifying subsets of a graph where every vertex is reachable from every other vertex within the same subset.
- Label Propagation, a semi-supervised learning algorithm for community detection in graphs, where nodes propagate their labels to their neighbors iteratively.
Reasons for ArangoDB’s Superior Performance
Several factors contribute to ArangoDB's superior performance:
The performance of ArangoDB on the Wiki-Talk dataset is attributed to specific architectural optimizations rather than on raw computational benchmarks. In this scenario, ArangoDB serves as a data storage system, while the computation is handled by the Graph Analytics Engine (GAE). The benchmark focuses on two key stages:
- Loading the data into the GAE
- Computation of algorithms within the GAE
Graph Loading Times
ArangoDB Side
ArangoDB’s graph loading times are optimized due to two primary factors:
- Parallel Data ExtractionArangoDB’s support for parallel data loading from both single and distributed systems is a big reason for data loading performance advantages. This capability lets teams scale to multiple machines, where increased parallelism gets you faster data transfer. By enabling efficient horizontal scaling, the system achieves significant performance improvements compared to approaches that are limited to sequential or that don’t leverage parallel extractions.
- Projections for Targeted Data TransferProjections allow ArangoDB to transmit only the data attributes required for analysis. So, if only edge IDs and a single attribute are needed, the system only extracts and transfers these fields, avoiding the overhead of transmitting entire documents. This reduces both the data volume and network latency during graph loading operations.
Graph Analytics Engine (GAE) Side
The GAE is built using RUST, and it processes the transferred data with high efficiency:
- Efficient Data Representation
The GAE stores graph data within highly optimized in-memory structures, reducing memory usage while at the same time maintaining extremely fast access speeds. Graphs are immediately ready for computation without unnecessary delays.
Advantages in the Workflow
These features deliver several tangible benefits, as shown during the benchmark:
- Fast and Parallel Data Extraction - Parallelism improves speed and scalability.
- Optimized Data Transfer with Projections - Only the required data is transmitted, minimizing overhead.
- Compact and Efficient In-Memory Representation in GA - High-performance graph computation with minimal memory footprint.
Clarifying the Benchmark Scope
It is important to note that the benchmark does not evaluate data insertion times into ArangoDB or computational tasks performed by ArangoDB itself. Instead, it assesses the efficiency of:
- Loading graph data from ArangoDB into the GAE.
- The GAE's ability to compute graph algorithms.
By highlighting these stages, the benchmark shows the advantages of ArangoDB’s design in supporting large-scale graph workflows through fast data loading and efficient interaction with the GAE.
Reproducibility of the Benchmark
This benchmark is 100% reproducible, ensuring consistent and verifiable results. These results reflect ArangoDB’s implementation per the precise specifications and configurations mentioned above. We welcome organizations to replicate the benchmark to ensure consistent results. To do this, follow these steps:
- First, set up the hardware environment with an Ubuntu 23.10 operating system, 192 GB of memory, and a Ryzen 9 7950X3D CPU.
- Install and configure the latest versions of Neo4j and ArangoDB using the provided Docker configurations. Use single-threaded (non-clustered) configurations for both.
- Next, utilize the wiki-Talk dataset for testing. Execute the specified graph algorithms (PageRank, WCC, SCC, Label Propagation) using the detailed workflows (A and B) outlined in the benchmark configuration above.
- Measure the in-memory graph creation and computation times, and compare the results for both databases. This method ensures that the benchmark can be reliably reproduced in different environments.
PLEASE NOTE: This benchmark requires the installation of the ArangoDB Graph Analytics Engine (GAE). As this code is not open source, please reach out to Corey Sommers at corey.sommers@arangodb.com to receive access to the GAE for the purposes of reproducing this benchmark in your environment (to ensure objectivity of results).
Conclusion
The benchmark results clearly demonstrate ArangoDB's far superior performance over Neo4j in the categories of graph computation and loading tasks. ArangoDB's significant speed advantages - particularly its ability to execute complex algorithms and load large datasets much faster - highlight its optimized architecture and efficient data handling.
These findings make ArangoDB a compelling choice for applications requiring high-performance graph analytics and real-time data processing.
Get the latest tutorials, blog posts and news: