 Skip to content
Skip to content 
Graph and Entity Resolution Against Cyber Fraud
Estimated reading time: 4 minutes
With the growing prevalence of the internet in our daily lives, the risks of malware, ransomware, and other cyber fraud are rising. The digital nature of these attacks makes it very easy for fraudsters to scale by creating thousands of accounts, so even if one is identified, they can continue their attacks.
In this blog post, we will discuss how graph and entity resolution (ER) can help us battle these risks across different industries such as healthcare, finance, and e-commerce (for example, the US healthcare system alone can save $300 billion a year with entity resolution). You will also receive hands-on experience with entity resolution on ArangoDB.
What is Entity Resolution?
Entity resolution, which is also referred to as record linkage or deduplication, is a technique used to identify and merge similar or identical entities from multiple data sources into a single record. Imagine, for example, a fraudster creating many thousands of accounts across different services. Entity resolution can help match these virtual records and resolve them into one entity or record.
Entity resolution can be used for a variety of purposes, such as identifying duplicate customer records in a marketing database, matching medical records to patients, detecting fraudulent activities by identifying multiple identities of the same person, or linking social media profiles to a single individual. Entity resolution can improve the accuracy and completeness of data by reducing redundancy, eliminating errors, and creating a unified view of the data. It can also be used to facilitate data integration and analysis, as well as support various applications such as recommendation systems, personalized marketing, and fraud detection.
User accounts: Merging multiple user entries into one entity.
Graph to the Rescue
Entity resolution is a challenge as there are typically no distinct keys identifying each entity.
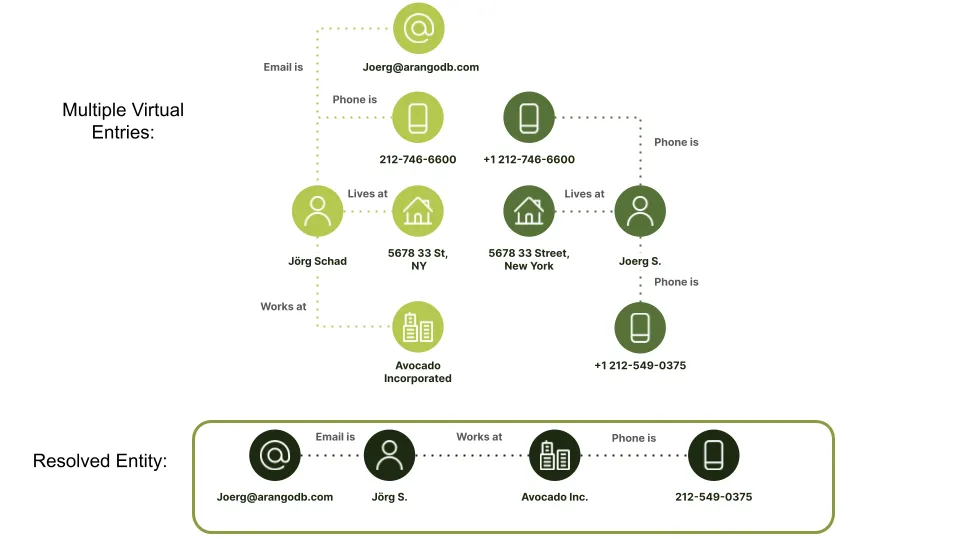
Let us revisit the above example of user accounts and experience one of my daily frustrations with the German umlaut in my first name. Depending on the document or account, it is either spelled Joerg or Jörg (let us not get even get started on pronunciation). Matching different accounts is a challenge because the name is not a unique identifier. This is often the case even without weird letters; just imagine J. Smith vs Joerg S.
Luckily, in most real world scenarios we have additional contextual information, such as emails, phone numbers, addresses, and employers. Here is where graph comes into play, as this information can be easily assembled as a graph. Note that usually the context won’t 100% match, e.g., I have multiple email addresses and phone numbers, moved around quite a bit, and worked for different companies, so vary rarely will all entities have all potential information categories (e.g., the account Joerg S. on the right side does not have connected employer information). Still, we can treat each individual piece as evidence and then compute a similarity score.
In practice, this can be done by representing the neighborhood of a user (i.e., a node in the graph) with similarity measures such as cosine similarity or Jaccard distance. Depending on the data, all nodes above a certain threshold are considered the same entity. Feel free to try yourself using this Jupyter notebook.
There are also other techniques, including graph machine learning, but we will cover that in more detail in another blog post.
How to Battle Cyber Fraud with ER
Entity resolution is used as a tool for cyber security by identifying and linking together various pieces of related information that can be used to catch fraudulent activity. This can include IP addresses, emails, or other means of device authentication. By analyzing these and other similar data points, entity resolution can help investigators detect the true identity of the fraudster and track their activities across multiple accounts or platforms.
There are several ways entity resolution can be used for cyber security. A few of these use cases include fraud detection, risk assessment, and identity verification. Some examples of entity resolution being put into play are identifying indicators of fraud, analyzing the risk associated with a particular transaction or user account, and verifying the identity of users through different identification methods.
Imagine a social media platform is trying to remove duplicate or fraudulent accounts. While there might be multiple accounts that go under the name Jane Foster, there would be a limited number of those accounts that would share a similar birth date. If you continue to narrow down your results, there may be 3 accounts under the name Jane Foster that use the same IP address and mobile device to connect to the duplicate accounts. This can also be used to identify spam accounts by associating devices and IP networks.
Learn More About Entity Resolution with ArangoDB
In this blog, we have discussed how graph and entity resolution can help with both cyber fraud and names with German umlauts! If you want to learn more about these topics take a look at the following additional resources.
Lunch + Learn Session
Entity Resolution in ArangoDB Blog Post
Fraud Detection with ArangoDB Webinar:
https://hopin.com/events/fraud-detection-with-arangodb
Jupyter Notebook
Get the latest tutorials, blog posts and news: