 Skip to content
Skip to content 
Introducing ArangoDB 3.8 – Graph Analytics at Scale
Estimated reading time: 5 minutes
We are proud to announce the GA release of ArangoDB 3.8!
With this release, we improve many analytics use cases we have been seeing – both from our customers and open-source users – with the addition of new features such as AQL window operations, graph and Geo analytics, as well as new ArangoSearch functionality.

If you want to get your hands on ArangoDB 3.8, you can either download the Community or Enterprise Edition, pull our Docker images, or start a free trial of our managed service ArangoGraph.
As with any release, ArangoDB 3.8 comes with many improvements, bug fixes, and features. Feel free to browse through the complete feature list in the release notes to appreciate all the work which has gone into this release.
In this blog post, we want to focus on some of the highlights including AQL Window Operations, Weighted Graph Traversals, Pipeline Analyzer and Geo Support in ArangoSearch.
AQL Window Operations
The WINDOW keyword can be used for aggregations over related rows, usually preceding and / or following rows.
The WINDOW operation performs a COLLECT AGGREGATE-like operation on a set of query rows. However, whereas a COLLECT operation groups multiple query rows into a single result group, a WINDOW operation produces a result for each query row:
- The row for which function evaluation occurs is called the current row
- The query rows related to the current row over which function evaluation occurs comprise the window frame for the current row
There are two syntax variants for WINDOW operations:
- Row-based (evaluated across adjacent documents)
- Range-based (evaluated across value or duration range)

Weighted Graph Traversals
Graph traversals in ArangoDB 3.8 support a new traversal type, "weighted", which enumerates paths by increasing weights.
The cost of an edge can be read from an attribute which can be specified with the weightAttribute option.
FOR x, v, p IN 0..10 OUTBOUND "places/York" GRAPH "kShortestPathsGraph"
OPTIONS {
order: "weighted",
weightAttribute: "travelTime",
uniqueVertices: "path"
}As the previous traversal option bfs was deprecated, the new preferred way to start a breadth-first search from now on is with order: "bfs". The default remains depth-first search if no order is specified, but can also be explicitly requested with order: "dfs".
ArangoSearch Pipeline & AQL Analyzers
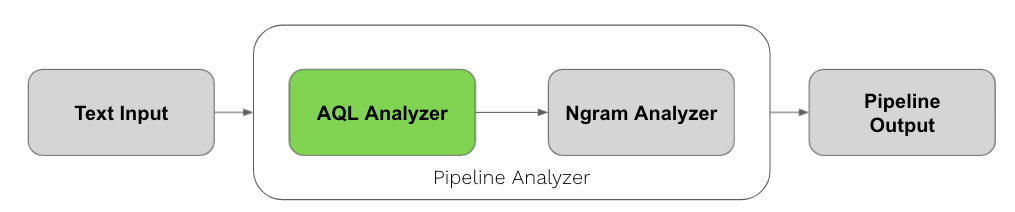
ArangoSearch added a new Analyzer type, "pipeline", for chaining effects of multiple Analyzers into one. This allows for example to combine text normalization for a case insensitive search with n-gram tokenization, or to split text at multiple delimiting characters followed by stemming.
Furthermore, the new Analyzer type "aql"is capable of running an AQL query (with some restrictions) to perform data manipulation/filtering. For example, a user can define a soundex analyzer for phonetically similar term search:
arangosh> var a = analyzers.save("soundex", "aql", { queryString: "RETURN SOUNDEX(@param)" }, ["frequency", "norm", "position"]);Note that the query must not access the storage engine. This means no FOR loops over collections or Views, no use of the DOCUMENT() function and no graph traversals.
Enhanced Geo support in ArangoSearch
While AQL has supported Geo indexing and functions for a long time, ArangoDB 3.8 adds Geo support also to ArangoSearch with the GeoJSON and GeoPoint analyzer and respective ArangoSearch Geo functions:
- Geo_Contains()
- Geo_Distance()
- Geo_In_Range()
- Geo_Intersects()
NB: Check out the community ArangoBnB project to learn more about Geo capabilities in ArangoSearch.
Improved Replication Protocol
For collections created with ArangoDB 3.8, a new internal data format is used that allows for a very fast synchronization of differences between the leader and a follower that is trying to reconnect.
The new format used in 3.8 is based on Merkle trees, making it more efficient to pin-point the data differences between the leader and a follower that is trying to reconnect.
The algorithmic complexity of the new protocol is determined by the amount of differences between the leader and follower shard data, meaning that if there are no or very few differences, the getting-in-sync protocol will run very fast. In previous versions of ArangoDB, the complexity of the protocol was determined by the number of documents in the shard, and the protocol required a scan over all documents in the shard on both the leader and the follower to find the differences.
The new protocol is used automatically for all collections/shards created with ArangoDB 3.8. Collections/shards created with earlier versions will use the old protocol, which is still fully supported. Note that such “old” collections will only benefit from the new protocol if the collections are logically dumped and recreated/restored using arangodump and arangorestore.
Other notable features
- UI and Visualizer Improvements
- Default per-query and optional global memory limits
- Metrics 2.0 version and user specific Grafana dashboards
- Arangodump improvements
- JavaScript security
- AQL bit functions
- Sorting performance improvements
- Agency Memory consumption
- Hardware acceleration for Encryption
Upgrade
Upgrading to ArangoDB 3.8 can be performed with zero downtime following the upgrade instructions for your respective deployment option. Please note our recent update advisory and update either to a newer 3.6/3.7 version or 3.8 if you are running an affected version.
ArangoGraph
The easiest way to give ArangoDB 3.8 a spin is ArangoGraph, ArangoDB’s managed service in the cloud.
Feedback
Feel free to provide any feedback either via our Slack channel or mailing list.
Special Edition Lunch Session
Join Simran Spiller on August 4th for a special Graph and Beyond Lunch Session #15.5 - Aggregating Time-Series Data with AQL.
The new WINDOW operation added to AQL in ArangoDB 3.8 allows you to compute running totals, rolling averages, and other statistical properties of your sensor, log, and other data. You can aggregate adjacent documents (or rows if you will), as well as documents in value or duration ranges with a sliding window.
In this lunch and learn session, we will take a look at the two syntax variants of the WINDOW operation and go over a few examples queries with visual explanations.
Hear More from the Author
Continue Reading
Introducing Developer Deployments on ArangoDB ArangoGraph
Get the latest tutorials, blog posts and news: