
Azure Now Generally Available on ArangoDB Oasis
Estimated reading time: 6 minutes
ArangoDB ArangoGraph, the cloud service of ArangoDB, has reached an important milestone. We are glad to announce that Azure support is generally available in ArangoDB ArangoGraph as of today!
Currently Azure is supported in the following regions:
- West US, Washington
- East US, Virginia
- Central Canada, Toronto
- UK, London
- West Europe, Netherlands
Why is this relevant?
When we launched ArangoGraph in November last year, we started with regions in the Google and AWS cloud. Even before our launch we already got lots of questions for supporting Azure regions.
While the reasons why people want to run on Azure differ, there is one common aspect. Once you have chosen a provider for your application, you want to run your database as close to your application as possible. This is important for latency, security and cost.
In the future, there will also be additional reasons. We will add more low-level support for in-provider connections. That means that the network traffic between your application and your database never leaves the network of the cloud provider. This again improves latency, security & cost.
What challenges did we face?
ArangoGraph is built on top of managed Kubernetes clusters. So it would be easy to argue that while Azure supports Kubernetes (with AKS) pretty well, adding Azure support to ArangoGraph would be straightforward.
Sadly that is not entirely correct. While Kubernetes really helps us a lot in abstracting away the underlying infrastructure, it is no silver bullet that magically makes all providers look alike.
Let’s start with the biggest challenge: Creating a new Kubernetes cluster
For this we have a set of so-called data cluster operators. One for each cloud provider.
One day the Cluster API will make it easy to create Kubernetes clusters on the fly using a single code base. Until that API is fully supported by all providers, we have to build our own code to create Kubernetes clusters for each cloud provider.
Azure comes with a decent set of APIs so writing a data cluster operator for Azure started off quickly.
Azure has a really nice concept, a resource group. This group concept made it really easy for us to keep track of all resources that belong to a single data cluster. It did not take us long until we had created our very first Azure data cluster (data cluster is a Kubernetes cluster in which we run ArangoDB ArangoGraph deployments).
Then came the challenges. Since our customers can choose deployments of different sizes, we use different size nodes to make the most efficient use of resources (memory & CPU). All the cloud providers have some concept of node pools that allow you to do so. But here came the catch.
On Azure, the number of node pools you can have is very limited: 10. This sounds reasonably large, but given that we already have 7 different node sizes we reach this limit very quickly. Even worse, the node pool also has a specific Kubernetes version. On the other cloud providers, we upgrade to a new Kubernetes version by adding node pools of the new version, then migrate all pods from the old nodes to the new ones and finally remove the old node pools. On Azure that is not an option because of the hard limit. To work around this, we have chosen to migrate pods 1 node pool at a time. While this works, it makes our upgrade procedures more complicated and we hope Microsoft will increase this limit in the near future.
Next challenge: Auto scaling
Another challenge we had, also related to node pools, was that node pools could not be scaled down to 0. For the other cloud providers, we rely on the cluster auto-scaler to add nodes when needed. That allows us to create node pools of all sizes and only pay for resources when they are actually needed. In the case of Azure we had to create a system that adds node pools when needed and removes them again when they are no longer needed.
Very recently this issue has been resolved by Microsoft. It is now possible to scale down node pools to 0 (this applies only to so-called user node pools). This change allows us to strip a significant number of lines of code from our data cluster operator for Azure.
Final challenge: Node reboots
The final challenge I want to address is that of node reboots. You would expect that when you add a node to your cluster, it already comes with the latest patches for the version that you selected. Sadly that is not the case in Azure. Within minutes after a node has been added it notices that it needs some updates and sets a flag indicating that a node reboot is required. If we had done nothing to counter this behavior, it would have been a rather unpleasant experience for ArangoGraph users. Imagine that you want to spin up a new deployment and after a few minutes your deployment is ready … just to find out that a few minutes later all servers will be restarted.
To counter this behavior, one of our infrastructure services running in a data cluster is catching the new nodes just before pods are scheduled on it. It marks them as unschedulable and proceeds with the node reboot as quickly as possible. After the node has been rebooted, the node is marked as schedulable and it can begin running pods.
Thank you Azure support!
As described above we faced quite a number of challenges while adding support for Azure.
During this entire process the support team of Microsoft has proven to be very helpful and responsive. Our answers were always answered in a timely manner and with decent content.
We were genuinely impressed by this experience! Well done Microsoft!
Which provider is next?
With the GA of Azure in ArangoGraph, the question arises which cloud provider will be supported next. At the time of writing this blog, that question has not yet been answered. We’re currently concentrating on several functional additions that we hope to announce soon.
If you have a need for a specific region that we do not yet support or a new cloud provider, please reach out to us. Use the Request help button on ArangoGraph to send a support request. If there is a clear demand for a region and/or provider we will act upon that.
What else is new in ArangoGraph?
ArangoGraph has made it very quick and easy to launch a new deployment. While this is great, you still have to bring your own data to “play” with it. That is no longer needed!
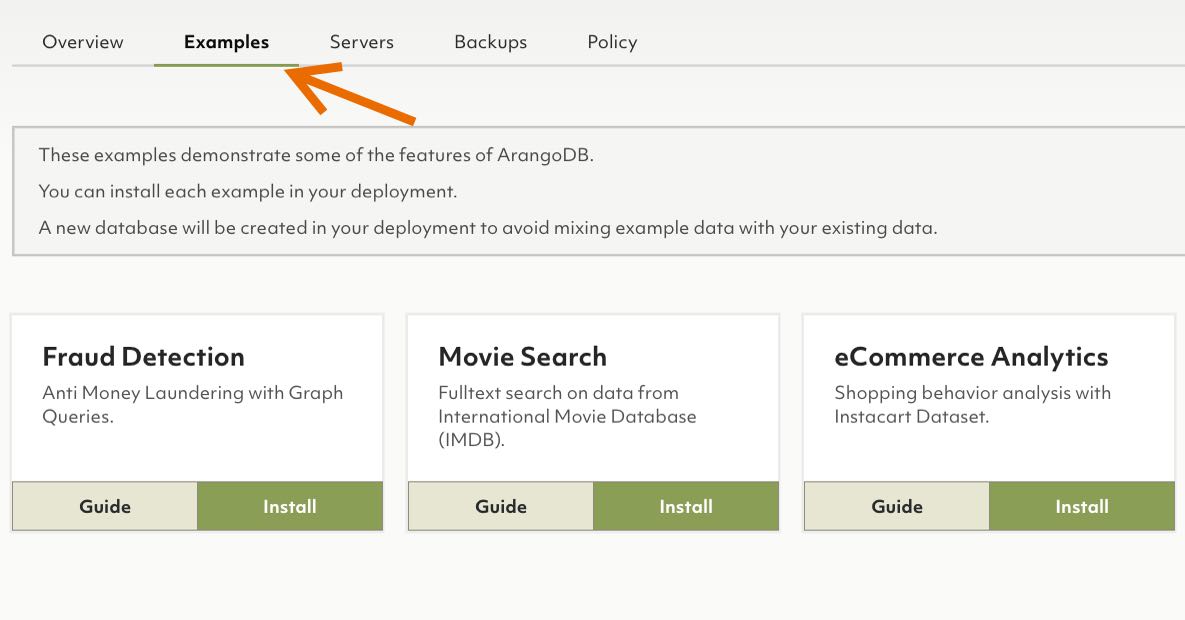
We added several example datasets that allow you to explore ArangoDB with real data in minutes. These examples install into a new database in your ArangoDB ArangoGraph deployment so installing them will not pollute any existing dataset.
Currently you have examples demonstrating graph capabilities for Fraud Detection, search features in a movie database and finally document analysis with an eCommerce dataset. More demos will follow.
You can install the example datasets and access the guides by navigating to your project. Just choose the deployment you want the demo data in, click on the “Examples” tab (see below) and hit “Install” for the example(s) you want to explore. You can also click “Install” during the creation of a new deployment and it will be installed automatically once the deployment is up and running.
How can I get started with ArangoGraph?
If you are new to ArangoGraph, just create a free account and deployment (no credit card needed). You will get a fully featured ArangoDB deployment for 14 days for free, no strings attached.
Hear More from the Author
OCB: Challenges in Building Multi-Cloud-Provider Platform With Kubernetes
Getting Started with ArangoDB ArangoGraph
Continue Reading
Get the latest tutorials, blog posts and news: