 Skip to content
Skip to content 
Building a Mini Database Cluster for Fun – LEGO Edition

ArangoDB is a native multi-model database that could be deployed as a single database, in active failover mode or as a full blown database cluster in the cloud. To try things out I can even run a cluster on my local development machine.
Well, yes... but I wanted to be more real, 24x7, with the opportunity to manipulate all the things…
Inspired by other Raspberry PI & mini-cluster projects, I thought I could build my own, bare metal, desk compatible Mini PC database cluster.Interested in trying out ArangoDB? Fire up your cluster in just a few clicks with ArangoDB ArangoGraph: the Cloud Service for ArangoDB. Start your free 14-day trial here
What's in it for me?
This blog post explains…
- How to setup Intel® Media Mini PC's as Linux servers
- How to deploy an ArangoDB cluster using SSL
- How to use a systemd service for production like configuration
- How to import JSON or CSV data into the DB
- How ArangoDB behaves in case of network chaos (resilience tests)
- How to add a new node to the database cluster
- How to perform rolling-upgrades in the cluster
Hard- and Software
Hardware

- 3 x Mini PC: Beelink 2 N4100
(4GB LPDDR4, 64GB eMMC 5.1, 2.4 GHz Intel Celeron N4100) - 1 x Mini PC: Beelink BT3 Pro Atom X5-Z8350 (optional)
(4GB DDR3, 64GB eMMC 5.1, 1.9 GHz Intel Atom X5) - 7" TFT display for Monitoring (optional)
- 5-port Gigabit Switch
- 5 x Cat 5e cable
- Some LEGO® to build a nice 7" rack
- USB stick, USB Keyboard (during setup)
Software
- Create bootable Live USB drives: https://unetbootin.github.io/
- Ubuntu 18.4 https://www.ubuntu.com/download/server
Mini PC
For my mini PC cluster project I decided to go with Intel(R) machines, even if ArangoDB runs on ARM64 quite well. I wanted to run the cluster 24/7 on my desk, being able to break connections or switch off the power supply whenever I want to.
After comparing several vendors and products, I decided to buy 3 Beelink S2 N4100 machines, usually intended to run as a media center in your home.

- Intel Celeron N4100, quad-core CPU @ 1.1 / 2.4 GHz
- 4GB DDR4 2400Mhz RAM
- 64 GB eMMC
The machines are totally quiet, no noisy fan and no issues with hot surfaces.
TFT Display
My database cluster is designed to fit on my desk and I want to be able to provide some cluster statistics while doing resilience tests, so I thought it's a good idea to add a 7" TFT display to the setting. I bought a cheap TFT from Wish-app for something like $46 or so. It's a 1024x768 screen with a HDMI connector that you usually can find in a rear-view setup of your car. Anyhow, it's great to show the current stats of my ArangoDB Mini PC cluster.

I will run the monitoring on the 4th machine using Prometheus. To be comfortable in a console-mode, I had to adjust the screen font size.
$> sudo vim /etc/default/console-setup
`FONTSIZE="16x32"`
LEGO® Tower
My 6yo son inspired me to use LEGO® bricks to build a small tower for my ArangoDB cluster. He contributed lot's of creative ideas and some of his construction vehicles to start the construction site.







Be creative how you want to build your rack, just make sure that you have access to all necessary ports and leave heating fences open to ensure air circulation.
The Mini PCs are lukewarm in idle state and only moderately heaten up, when under load. The cluster is SILENT at all times and looks beautiful on your desk!
Setup Ubuntu Linux and Network
The Beelink Mini PCs run Windows 10 by default as they are intended to run as media server in your home. To change the OS to Linux I need to boot the server from a USB stick.
To create a bootable USB drive I simply used unetbootin that runs on all environments and is super easy to use. (I'm on a Mac)
For my server project I want to run a Linux cluster using Ubuntu server.
Starting unetbootin I chose disk image, select the fresh ISO of Ubuntu linux, the correct USB drive and press OK. A couple of minutes later my bootable Ubuntu USB drive is ready to use.
Now head to each Mini PC and get rid of Windows 10…
First, insert the USB stick into the Mini PC. To change the boot sequence, I run the boot menu holding the ESC key during boot. The Beelink uses the Aptio Setup Utility by American Megatrends. I change the Boot Option #1 from Windows Boot Manager to my inserted USB stick via UEFI. Save + Exit and Ubuntu starts and allows to setup on the local disk.
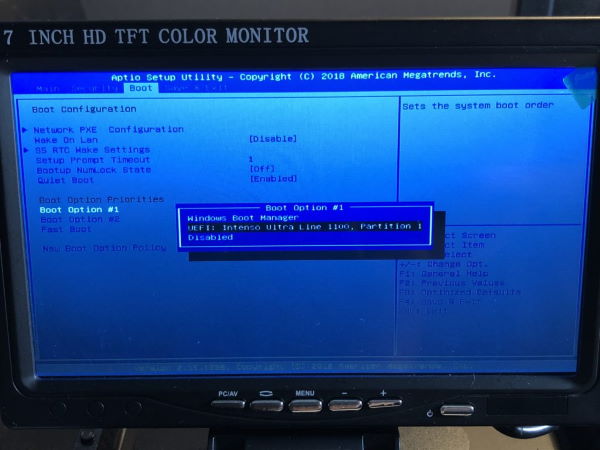
During the installation I name the servers node1, node2 and node3 - these will build the cluster - and serv01 for the additional one. My user arangodb has the same credentials on all nodes.
After installing Ubuntu I do an upgrade to get the latest packages.
$> sudo apt update $> sudo apt dist-upgrade
Hint: If you're a Mac-only household, you may also want to change the keyboard layout via
`sudo dpkg-reconfigure keyboard-configuration`.
Network Setup
My network currently relies on DHCP with a dynamic IP - but I want to use static ones instead. My colleague granted me some static IP addresses in the range 172.30.0.0-172.30.255.255.
I use netplan in Ubuntu to configure my network. There is an existing .yaml file that I use to define my static IP addresses:
$> sudo vim /etc/netplan/50-cloud-init.yaml
network:
ethernets:
enp2s0:
addresses: [172.30.0.11/12]
dhcp4: yes
dhcp6: no
gateway4: 172.31.255.254
nameservers:
addresses: [8.8.8.8, 8.8.4.4]
version: 2
My nodes of my cluster will get the following IPs:
172.30.0.11 node1
172.30.0.12 node2
172.30.0.13 node3
Now I have to apply the network changes:
$> sudo netplan apply
I could validate that my IP address is set correctly with
$> ip add
Useful Tools & Commands
I learned to enjoy working with tmux, a tool that allows me to run commands on several machines at once (connected via SSH).
Starting a process like ArangoDB with a detachable console is useful as well. The command screen without parameters does the job. Now I can run arangodb and could detach the console using <ctr>+<a> <d>. If I want to get back I can use screen -r later again.
Working with JSON is much easier if you know jq. It's a powerful tool to manipulate JSON files or pretty-print on the console. Just pipe to jq.
$> cat dataset.json | jq .
Setup Database Cluster using ArangoDB Starter
One of several ways to setup a 3 node cluster is to use the ArangoDB starter. With a single command on each machine you can launch a database cluster.
$> arangodb --starter.data-dir=/home/arangodb/data \
--starter.join 172.30.0.11,172.30.0.12,172.30.0.13
Of course you can also run ArangoDB using Docker in the same way or use a Kubernetes cluster with the ArangoDB operator to start a cluster.
Let's get into the details using the starter…
First, I download the Enterprise Edition of ArangoDB from the download section of our homepage, which is free for evaluation, here the .tar.gz package (a universal binary), and copy it to the three servers:
$> scp arangodb3e-linux-3.4.0.tar.gz arangodb@172.30.0.11:/home/arangodb/
A love letter to static binaries
With 3.4 ArangoDB has introduced static binaries, .tar.gz packages, that could be extracted anywhere in the file system and just run.
No more wondering what kind of dependencies need to be installed, how to run multiple versions in parallel or how to get rid of an application easily.
The folder structure looks like that after extracting the files using tar -xzf arang…:
arangodb3e-3.4.0/ bin/ usr/ README
In my .profile I add the path to the PATH variable.
PATH=/home/arangodb/arangodb3e-3.4.0/bin:$PATH
CA and Certificates
We now want to secure the server using TLS. The arangodb starter supports us by providing commands to build a self-signed CA and generate certificates and TLS keyfiles. A detailed description could be found in the documentation.
$> arangodb create tls ca
Creates CA certificate & key in tls-ca.crt (certificate), tls-ca.key (private key). Make sure to store the private key in a secure place. The CA certificate should be imported to the browser to assure that certificates signed with this CA could be trusted.
$> arangodb create tls keyfile --host 172.30.0.11 \
--host 172.30.0.12 \
--host 172.30.0.13
This command creates the tls.keyfile that should be copied to the data directory with the name arangodb.keyfile and permission 400.
JWT Secret
In the default cluster setup using the Starter, each node fires up an agent, a coordinator and a db server. Read more in the documentation (ArangoDB Starter Tutorial).
The ArangoDB starter allows me to generate a JWT token that could be used for authentication as super-user. This role is needed to communicate with the agency or any db server directly.
$> arangodb create jwt-secret --secret=arangodb.secret
The file on my server with the name arangodb.secret consists of a single line with a 64 character JWT token. This needs to be copied to all nodes and is used when we use the starter to setup and run the cluster.
I am using /etc/hosts entries to match the IP addresses to hostnames (node1, node2, node3).
Starting a detachable screen console, I can now start my cluster:
$> screen
$> arangodb --ssl.keyfile=/home/arangodb/arangodb.keyfile \
--starter.data-dir=/home/arangodb/data \
--starter.join node1,node2,node3 \
--auth.jwt-secret=/home/arangodb/arangodb.secret
Make sure that you use the same setup on all machines so you can run the same command on all nodes. Now I can detach the console using <ctr>+<a> <d>. If I want to get back I can use screen -r later again.
Automate using a systemd Service
With the above mentioned setup I don't want to go "productive". As I want to do resilience tests - unwire LAN, do random reboots - I want to restart ArangoDB via a systemd service automatically.
To keep the setup clean and consistent, I define some environment parameters in a file /etc/arangodb.env and move the JWT secret to /etc/arangodb.secret .
$> vim /etc/arangodb.env
DATADIR=/var/lib/arangodb3/cluster CLUSTERSECRETPATH=/etc/arangodb.secret TLSKEYFILE=/etc/arangodb.keyfile STARTERADDRESS=172.30.0.11 STARTERENDPOINTS=172.30.0.11:8528,172.30.0.12:8528,172.30.0.13:8528
First, I add the service configuration in /etc/systemd/system/arangodb.service
[Unit]
Description=Run the ArangoDB Starter
After=network.target
[Service]
User=arangodb
Group=arangodb
Restart=always
KillMode=process
EnvironmentFile=/etc/arangodb.env
ExecStartPre=/bin/sh -c "mkdir -p ${DATADIR}"
ExecStart=/home/arangodb/arangodb-3.4/bin/arangodb \
--starter.data-dir=${DATADIR} \
--ssl.keyfile=${TLSKEYFILE} \
--starter.address=${STARTERADDRESS} \
--starter.join=${STARTERENDPOINTS} \
--server.storage-engine=rocksdb \
--auth.jwt-secret=${CLUSTERSECRETPATH} \
--all.log.level=startup=debug \
TimeoutStopSec=60
[Install]
WantedBy=multi-user.target
This configuration is the same on all machines, easy to understand and to adjust.
Hint: The KillMode=process allows me to later kill the arangodb starter process without killing child processes (db server, coordinator, agency) what comes handy during a rolling upgrade.
Now let's enable our new service:
$> sudo systemctl enable arangodb
This will create a symbolic link from the system's copy of the service file into the location on disk where systemd looks for autostart files.
$> systemctl start arangodb
Now run the starter on all machines using systemctl:
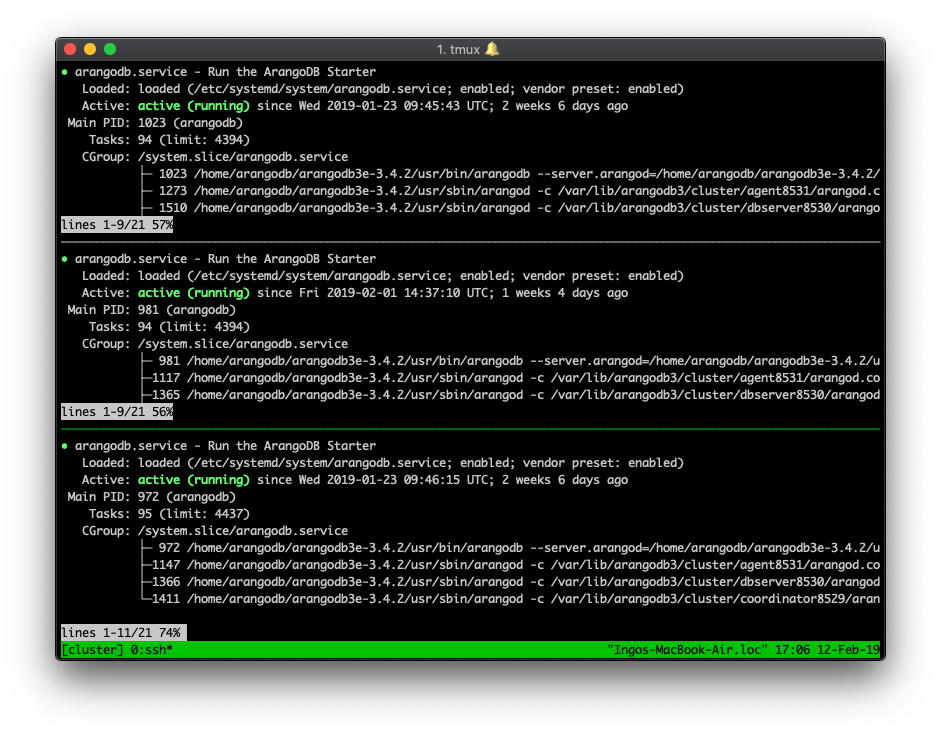
First of all the cluster should now start on all machines. You can check the status of the service using:
$> systemctl status arangodb
Here you can see the main process and the 3 sub-processes of arangod that start the corresponding DB services.
arangodb.service - Run the ArangoDB Starter
Loaded: loaded (/etc/systemd/system/arangodb.service; enabled; vendor preset: enabled)
Active: active (running) since Wed 2019-01-23 08:51:58 UTC
Process: 27119 ExecStartPre=/bin/sh -c mkdir -p ${DATADIR} (code=exited, status=0/SUCCESS)
Main PID: 27121 (arangodb)
Tasks: 86 (limit: 4437)
CGroup: /system.slice/arangodb.service...
├─27394 /home/arangodb/arangodb3e-3.4.0/usr/sbin/arangod -c /var/lib/arangodb3/cluster/agent8531/arangod.conf --database.directory /var/lib/arangodb3/cluster/agent8531/data --ja
├─27518 /home/arangodb/arangodb3e-3.4.0/usr/sbin/arangod -c /var/lib/arangodb3/cluster/dbserver8530/arangod.conf --database.directory /var/lib/arangodb3/cluster/dbserver8530/dat...
├─27552 /home/arangodb/arangodb3e-3.4.0/usr/sbin/arangod -c /var/lib/arangodb3/cluster/coordinator8529/arangod.conf --database.directory /var/lib/arangodb3/cluster/coordinator85...
└─27121 /home/arangodb/arangodb3e-3.4.0/usr/bin/arangodb --server.arangod=/home/arangodb/arangodb3e-3.4.0/usr/sbin/arangod --server.js-dir=/home/arangodb/arangodb3e-3.4.0/usr/sh...
Configuration Changes / Troubleshooting
If you have a typo in your definition or you want to change something in the configuration, you need to reload the daemon:
$> systemctl daemon-reload
Now you may want to restart the database service as well:
$> systemctl restart arangodb
The commands journalctl -xe and the systemctl status arangodb provide you with more details in case of any issue (e.g. missing file permissions)
A short tutorial on how to use systemctl could be found on DigitalOcean.
ArangoDB Web UI
ArangoDB comes with a built-in WebUI, just move your browser to the IP address of one node, port 8529 and you get a login screen. The default user is root with no password set.
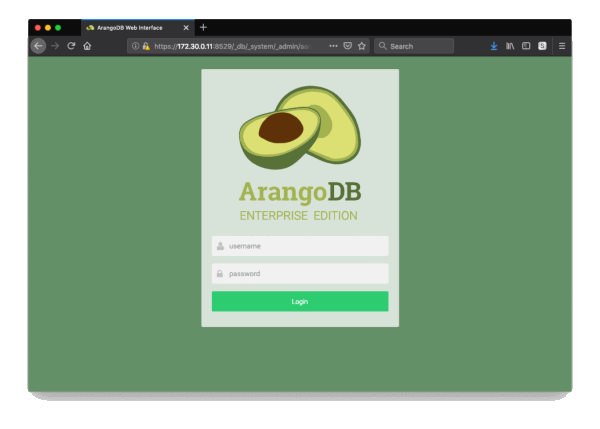
By importing the CA certificate into your browser, this site should appear right away. If not, you need to explicitly allow access to continue.
Make sure to set a password after the first login.
The Web UI allows you to administrate your database, collections, search views, and more. You can also use a query editor to execute or profile queries expressed in AQL.
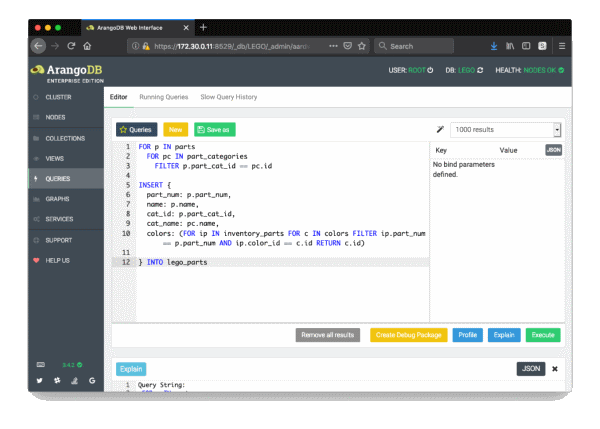
You can learn more about the WebUI, drivers, HTTP API and AQL in the ArangoDB training center.
Monitoring
You should monitor your database cluster, e.g. with collectd and Prometheus which is described in a tutorial here. Please monitor your volumes properly. If you are running out of disk space, it's not fun at all to watch rocksDB suffering.
Cluster Health
Using the administration API we could access some relevant data regarding the health of the cluster as JSON. Piped to jq you might even be able to read it. ;-)
Create bearer authentication token:
$> curl -k -d'{"username":"root","password":"myPassword"}' https://172.30.0.11:8529/_open/auth
Request cluster health data using token auth:
$> curl -k -X GET "https://172.30.0.11:8529/_db/_system/_admin/cluster/health" \
-H "accept: application/json" \
-H "Authorization: bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ…MV_9K2kk="\
| jq

This API reveals the current status of all cluster parts, which should be monitored using Prometheus or similar tools.
A lot more information could be gathered if one uses the tool arangoinspect, which collects all recent log and environment data.
How to work with arangoinspect deserves a separate blog post (@see: cluster dump).
Import Test Data
There is a relational LEGO dataset available at Kaggle (CSV files). These could be easily imported using arangoimport.
arangoimport --server.endpoint ssl://172.30.0.11:8529 \
--server.database lego \
--collection sets \
--type csv \
--file /home/arangodb/lego/sets.csv
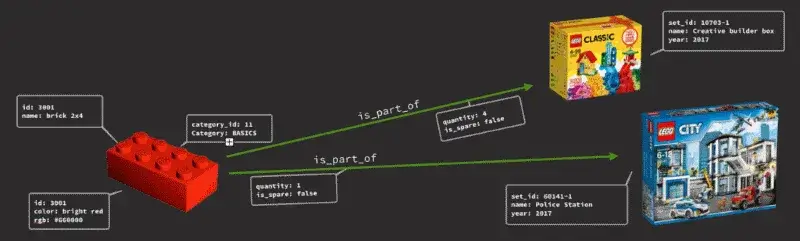
As you can model your data as JSON documents we could simplify the data model and transform the dataset (using AQL) into fewer documents and edge collections that link from parts to actual sets. If you are new to graph database concepts, you can learn first graphdb skills in this free course.
Adding another edge collection with sets_we_own could lead to interesting new use cases.
Where does the part 60219 in Dark Bluish Gray belong to?
WITH lego_sets
FOR part IN lego_parts
FILTER part.part_num == @part_num
FOR set,edge,p IN 1 INBOUND part is_part_of
FILTER p.edges[0].color.id == @color_id
RETURN set

Feel free to add a ML brick-recognition approach like the Sorter in "Sorting 2 Tons of Lego" and I'm your first customer…
Resilience Tests
The agents perform a crucial role in the maintenance of a cluster. The leader…
- monitors heartbeats from coordinators and db servers and keeps track of their health
- takes action, when database servers have gone missing for longer than a grace period
- Shard leaders are replaced by an in-sync follower. And a new follower is added, if available.
- Shard followers are replaced by any available db server, which does not already replicate this shard as follower or leader.
- Once any of the above has finished, the failed server is removed from the shards server list.
- handles cleaning out of db servers on user request
- handles moving of shards per user request
More details on database cluster architecture and the cluster agency can be found on our website or directly in our documentation.
Resilience - The Tests
The database cluster is up and running and I can play a bit with the data. Cluster operations run smoothly and my little 3 node cluster performed as expected. But after a while, strange things happened…
Apparently, my son hid two suspicious characters in the LEGO® rack of my ArangoDB database cluster. Those were really nasty and tried to perform physical harm to my cluster.

First, Mr. E., wearing the red Oni-Mask,
pushed the power button for a few seconds and one machine died
immediately. The ArangoDB agency noticed the missing heartbeats and
thanks to replication factor 2, my sharded collections were moved to the two active nodes.
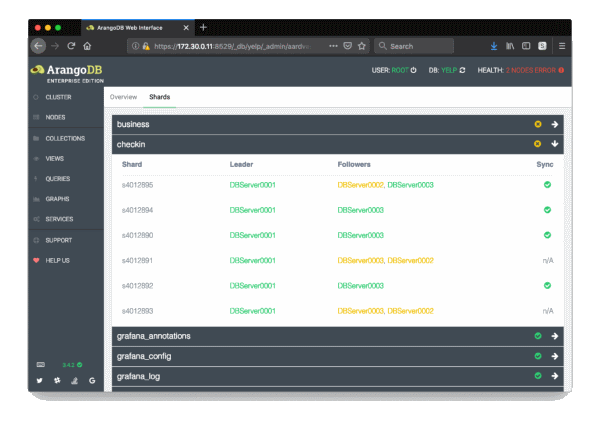
Within a few seconds, the first shards were already moved to the second server. Now I would probably spin up a new ArangoDB on the 4th standby node.
OR, as my cluster stands right in front of me, I can just hit the crook on the fingers and switch the node on again. You now have to move shards manually or use the rebalancing feature.
Second, Garmadon was tampering with the network cable. Network partitioning, what a mess.

Same procedure as before, the remaining agency instances noticed the missing db server, elected a new leader for the shards that were lead by the missing server and started rebalancing. Meanwhile the lonely server tries hard to locate the database cluster. This time, I was able to snatch the cable from the intruder quickly and put it back into the server.
The db server was back in the network and could read the updated cluster plan. He observes that he's not the leader for certain shards any more. The rebalancing jobs for shards, of which he was a follower, which started when the db server was unavailable, will stop eventually and allow the server to catch up again.
Adding a Node
In case one of the 3 nodes of my cluster is permanently down, I want to replace this node. The setup is similar to all the other nodes.
For the --starter.join endpoints I just need to refer to one existing node, so I modify the file etc/arangodb.env accordingly:
STARTERADDRESS=172.30.0.10
STARTERENDPOINTS=172.30.0.11:8528,172.30.0.13:8528
$> systemctl reload-daemon $> systemctl start arangodb
The service starts and connects to one of the existing nodes and appears in the cluster configuration. If you added a node to replace a failed one, you might now want to remove the old "officially" from the cluster using the trash icon in the Web UI.
Rolling Upgrade
Now it's time to upgrade to the latest patch-release of ArangoDB, as of today that's 3.4.2. As I use the static binary, I first need to download the latest .tag.gz, copy it to all nodes, extract it and prepare the rolling upgrade.
Second, edit /etc/systemd/system/arangodb.service and adjust the path to the new version and restart the daemon
$> systemctl daemon-reload
Third, use systemctl status arangodb to get the PID of the arangodb starter and kill the process with kill -9 PID. The service configuration with the line KillMode=process takes care that all subprocesses continue (!).
The systemctl daemon will restart the arangodb starter immediately, this time the new one. Now we have:

The final step is to run the rolling upgrade. Therefore I start arangodb on just one node and start the upgrade process.
$> arangodb upgrade --starter.endpoint=https://172.30.0.11:8528
This contacts the already running new starter processes and performs the upgrade.
Wrap Up
- Media servers (Mini PCs) with 4GB RAM are perfectly suited to build a desk compatible, totally silent database cluster. LEGO® allows you to get creative and build beautiful cluster racks.
- ArangoDB Starter & static binaries makes deployment of ArangoDB database clusters very easy and robust.
Read on:
- ArangoDB Cluster Course: Learn all internals and details of database cluster setup. E.g. fine tune deployment of agency/ coordinators/ db servers on each node.
Get the latest tutorials, blog posts and news: