 Skip to content
Skip to content 
Sharding: freedom, when you need it least?
“I must have a prodigious amount of mind;
it takes me as much as a week, sometimes, to make it up!”
― Mark Twain
How many shards should one choose, when creating collections in ArangoDB clusters?
TLDR: Don’t be too shy with sharding your data in many shards across your cluster. Be mindful however that AQL-heavy applications might not profit as much from heavy distribution.
How a database works and performs in a single instance setup is becoming more and more irrelevant lately, if said database cannot scale. Distributed, clustered databases are, as far as one can tell right now, the future.
Clustering immediately implies two new degrees of freedom. On the one hand one needs to answer how many replicas one wants or needs to make sure, that the added hardware is used to obtain more data safety, reflected in the `replicationFactor` property of collections. While on the other hand there is sharding, a concept that covers the actual distributed nature of the data operation.
Now this really sucks, as if it were not already enough trouble out there, one buys some more by introduction of two more parameters to worry about.
The replication factor is a rather easy one and is most readily answered, when answering what the data in question is worth? Are we looking at volatile session data, the balance of an insurance policy or the nuclear codes? For the first a replication factor of 1 might be already too much. The second probably could do with a couple more `2 < n < 5`. While the third you probably must not ever consider saving in a database? Serious aside for a moment: the gist is clear.
But what about sharding? This one actually does require a little bit of attention beyond the obvious.
Before we dive in, just a quick walk-through to the cluster architecture of ArangoDB. As you can see in the schema below, there are 3 roles when ArangoDB in cluster mode.
Interested in trying out ArangoDB? Fire up your cluster in just a few clicks with ArangoDB ArangoGraph: the Cloud Service for ArangoDB. Start your free 14-day trial here
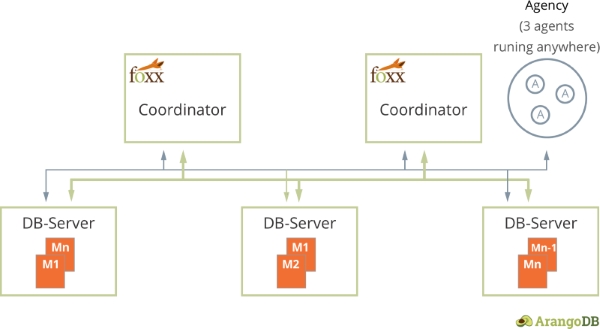
Coordinators are stateless, handle all incoming queries and are the place where Foxx services live. DBservers are stateful and store the actual data. Agents form the Agency which is basically the brain of the cluster management.
Let’s take 5 boxes, where ArangoDB is supposed to run in a 3 agent, 5 coordinator, 5 database server setup and a collection with 200GB of a shop’s product catalogue. How should the collection be sharded?
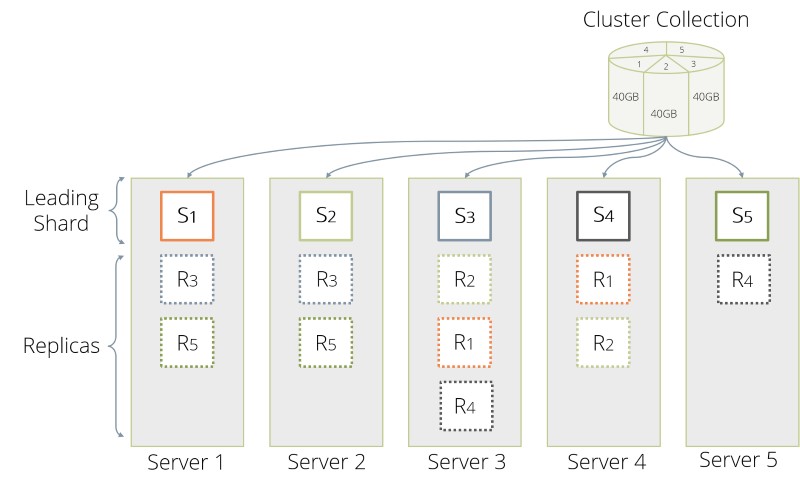
To answer that we need to appreciate, that every shard is a local collection on any db server, that houses such a shard as depicted above for our example with 5 shards and 3 replicas. Here, every leading shard S1 through S5 is followed each by 2 replicas R1 through R5. The collection creation mechanism on ArangoDB coordinators tries to best distribute the shards of a collection among the db servers. This seems to suggest, that one shards the data in 5 parts, to make best use of all our machines. For sake of reason-ability, we further choose a 3 as replication factor as it is a reasonable compromise between performance and data safety. This means, that the collection creation ideally distributes 15 shards, 5 of which are leaders to each 2 replica. This in turn implies, that a complete pristine replication would involve 10 shards which need to catch up with their leaders.
The 200GB are uniformly distributed, so the complete overall replication entails replication of 40GB of data per follower and shard. All replication processes run in parallel. So across our 5 server some 10 replication processes are running. This is all the while requests keep coming in carrying writes and reads to our collection.
Further, the more data needs to be replicated per shard, the longer every such initial replication process is going to be running with all sorts of consequences of long running processes. Also let’s not forget that the constant IO to the system involves the leaders of the five shards for as long as the replication is catching up.
From the above it seems intuitive to want to break up the process some more to have individual replications to not have to do as much each, hoping that memory allocation remains smaller per process. And to help the statistics help us in distributing the load more evenly.
And also let’s think a year or so down the road of our successful project, so that in the meantime we have grown to 10 database servers to meet the increased demands. As ArangoDB’s default and in most cases best sharding mechanism is by evenly distributing the `_key` property of each document, all data would need to be resharded, i.e. copied to a new collection with higher number of shards, one would avoid the, in the meantime, 2TB copy all together, if one had started off with say 50 shards, by simply clicking on the Rebalance Shards button in the UI.
So should one not just use a lot of shards? Not so fast. As long as your application is not too `AQL` heavy. The reason lies in the way in which AQL queries are broken down and optimized as a spider-web of back and forth between coordinators and db servers. Here, the less elaborate that spider-web is, the better is the performance of the queries.
2 Comments
Leave a Comment
Get the latest tutorials, blog posts and news:
is possible to start with one shard strategy and then if the business required move to multiple shards? this for a graph
Nearly everything is possible, if you can spend a little downtime later to reshard your collections. Also please keep your sharding concept (specifically sharding key) in mind for later. Also you might want to test performance impact before the big day, so that you are not surprised by the performance impact of a unoptimised sharding.