
How We Wronged Neo4j & PostgreSQL: Update of ArangoDB Benchmark 2018
Recently, we published the latest findings of our Performance Benchmark 2018 including Neo4j, PostgGreSQL, MongoDB, OrientDB and, of course, ArangoDB. We tested bread & butter tasks in a client/server setup for all databases like single read/write and aggregation, but also things like shortest path queries which are a speciality for graph databases. Our goal was and is to demonstrate that a native multi-model database like ArangoDB can at least compete with the leading single model databases on their home turf.
Traditionally, we are transparent with our benchmarks, learned plenty from community feedback and want to keep it that way. Unfortunately, we did something wrong in our latest version and this update will explain what happened and how we fixed it.
What we did Wrong
Max De Marzi and JakeWins from team Neo4j rightfully pointed out in a lively discussion on HackerNews, that the new NodeJS driver for Neo4j supports connection pooling. The old driver used in our previous benchmark didn’t support pooling and we used 25 requests via NodeJS to Neo4j instead (concurrency). The new driver supports now connection pooling. We missed that… Sorry, Team Neo4j and thanks for your contribution!
As using concurrency compared to connection pooling might lead to unnecessary overhead and a potential disadvantage for Neo4j, we updated our benchmark suite and reran all of the tests. Thank you Max and JakeWins for helping us to improve our benchmark!
On the PostgreSQL side, CEO & Founder of ToroDB, Alvaro Hernandez (ahachete on HackerNews) reported a potential problem with our benchmark related to PostgreSQL. This was very surprising for us — maybe even to all non-Postgres people out there — but also correct: PostgreSQL starts by default with a main memory cap of just 128MB! Alvaro pointed us to a configuration tuning tool he created to overcome this limitation and create the same fair test conditions for PostgreSQL, as well. Thanks so much for your contribution, Alvaro!
Now that all of the benchmark scripts have been updated and the benchmark was run again, let’s dive into the new results.
The Effects of the Fixes
In some test cases, using connection pooling instead of concurrency improved significantly the stats for Neo4j, but also led to a performance decrease in other test cases and even more memory consumption in general. The reduced overhead of connection pooling compared to concurrency setup is measurable and had a positive impact on single write sync, finding neighbors of neighbors as well as finding 1,000 shortest paths. The chart below shows the impact of using connection pooling compared to the concurrency setup numbers we initially published.
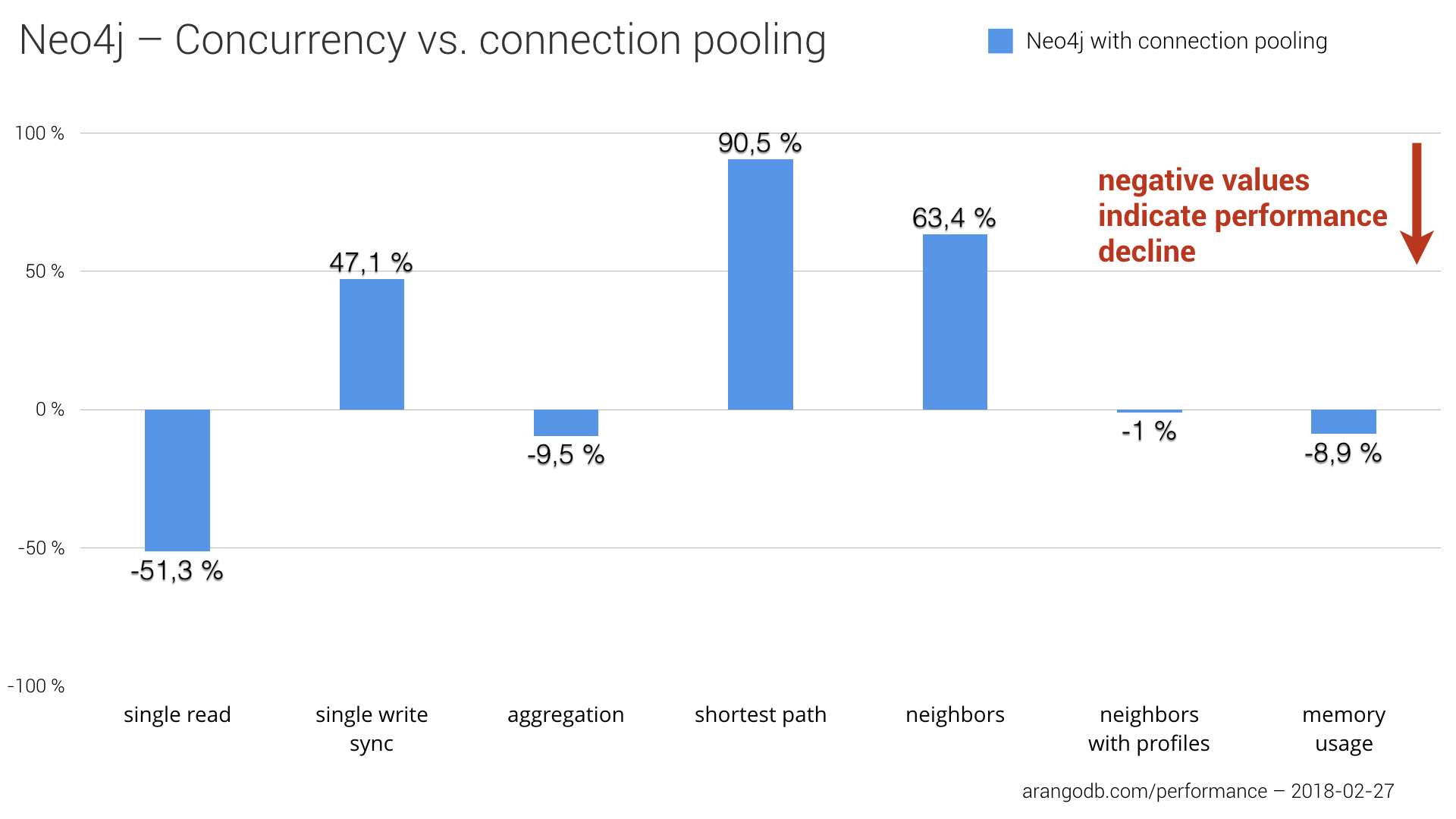
The shortest path test especially finished much faster with an approximately 90% performance gain. Despite the noticeable slowdown in single reads, even more memory consumption and slight worsening in aggregation computing, we can think that switching to connection pooling for Neo4j had an overall positive effect on Neo4js benchmark results in absolute numbers. To get the full picture, we have to put those numbers into context with the results of the other products, of course. You can find the complete stats in the next section.
We also reran the benchmark for PostgreSQL with the following configurations using the PGTune calculator recommended by Alvaro.
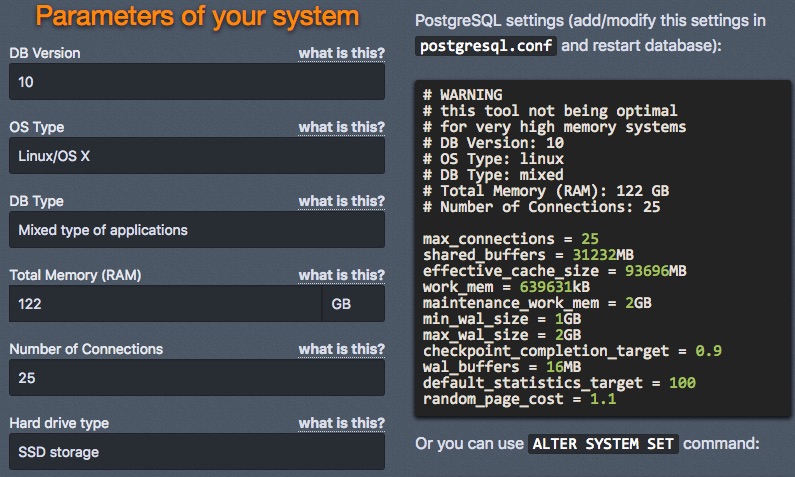
Implementing the generated tuning parameters for PostgreSQL into our benchmark didn’t lead to significant performance changes. We assumed that the already very fast SSDs of the i3 instances we used in our benchmark, provided a good setting for PostgreSQL already, so that the memory cap of 128MB did not affect the stats, too much. Nonetheless, we will keep this update for potential future releases of our open-source Performance Benchmark Series.
Please note: We did a baseline run of the restarted benchmark instances on AWS and validated that the machines we used for the update to this benchmark are comparable to the machines we had for the initial benchmark post.
Effect of Connection Pooling for Neo4j on Overall Results
In a nutshell, it’s true that connection pooling achieved better performance of Neo4j, but it didn’t change the overall ranking much.
In the overview below, we again used ArangoDB (RocksDB engine) as our baseline (100%). Higher percentages mean that execution time was slower compared to the baseline. Despite the performance increase of Neo4j, the overall ranking of the databases stayed basically the same.
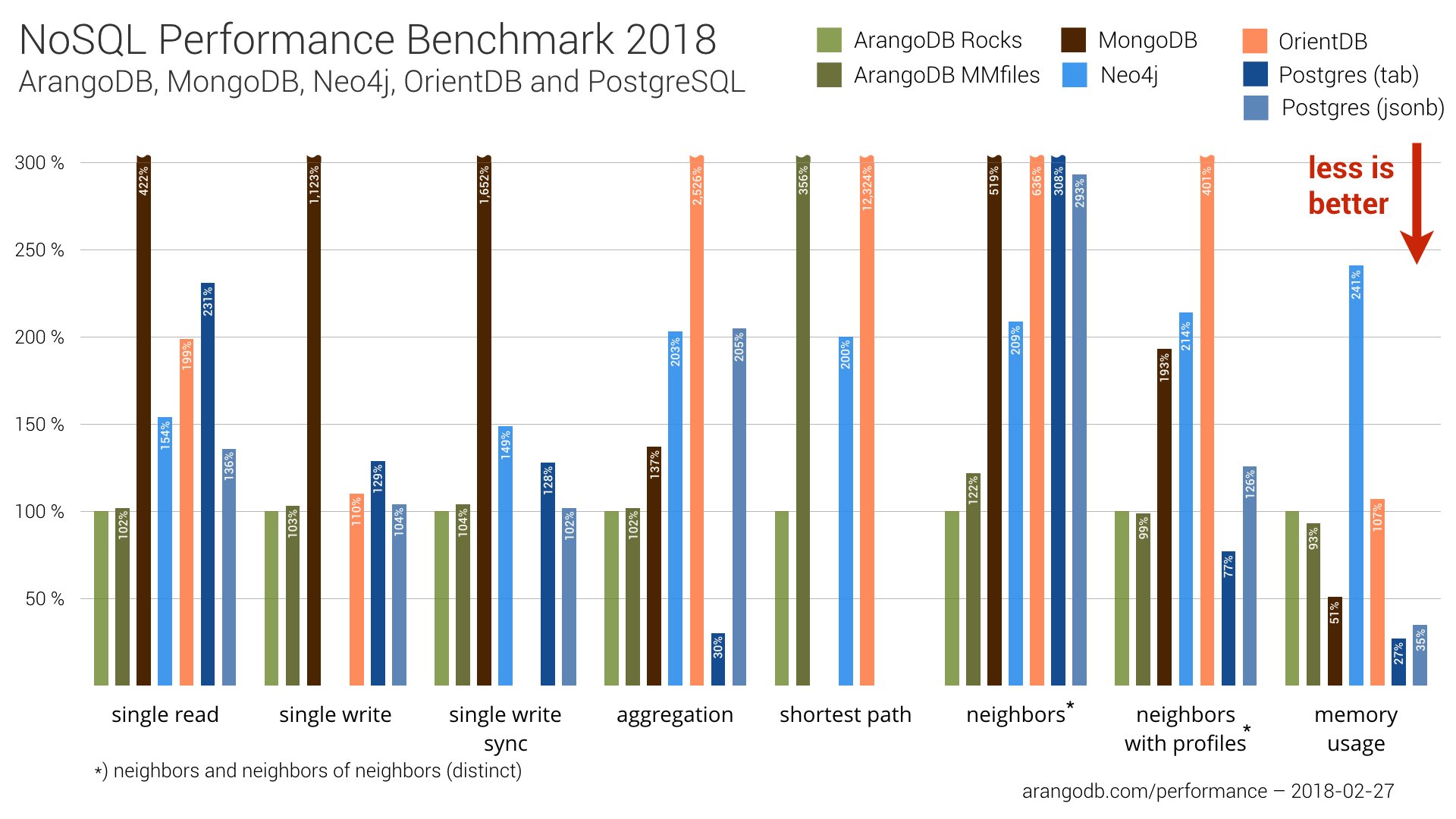
For the shortest path test (i.e., finding 1,000 shortest paths), Neo4j went from ranking third to second place. But ArangoDB with RocksDB is still twice as fast.
We also observed a slight ranking improvement for Neo4j at finding neighbors-of-neighbors. Neo4j now ranks third instead of fifth behind ArangoDB with MMfiles and particularly RocksDB engine, which returned the 1,000 vertices in 1.43 seconds compared to Neo4j with ~3 seconds.
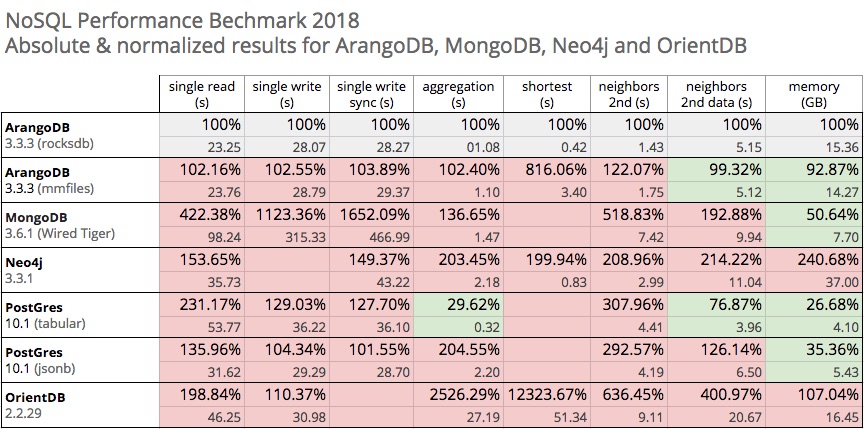
The table below includes all normalized as well as absolute numbers of the updated benchmark results:
Again, as JakeWins pointed out on HackerNews, “benchmarks are hard”. We do our best to create fair conditions for all of the included databases. However, sometimes something just falls through the cracks in such complex projects. We hope this update includes now the right setup for all of the products. Please let us know your feedback if you find something we can improve.
Of course, we updated the original post, as well. Please find all of the details about the benchmark test cases, the AWS instances used, and all of the other specifications in the NoSQL Performance Benchmark 2018 post.
We are well aware of the fact that different use cases or test cases will change results and rankings. The benchmark and the published scripts hopefully can act as a first orientation, and as a boilerplate for your own use cases. Still, we encourage you to run your own tests.
Get the latest tutorials, blog posts and news: