 Skip to content
Skip to content 
ArangoML Pipeline: Simplifying Machine Learning Workflows
Over the past two years, many of our customers have productionized their machine learning pipelines. Most pipeline components create some kind of metadata which is important to learn from.
This metadata is often unstructured (e.g. Tensorflow’s training metadata is different from PyTorch), which fits nicely into the flexibility of JSON, but what creates the highest value for DataOps & Data Scientists is when connections between this metadata is brought into context using graph technology…. so, we had this idea… and made the result open-source.
We are excited to share ArangoML Pipeline with everybody today – A common and extensible metadata layer for ML pipelines which allows Data Scientists and DataOps to manage all information related to their ML pipelines in one place.
Find ArangoML Pipeline on GitHub including demo and detailed walk-through.
What is ArangoML Pipeline?
Machine learning pipelines contain many different components: Distributed Training, Jupyter Notebooks, CI/CD, Hyperparameter Optimization, Feature stores, and many more.
Machine Learning Pipeline
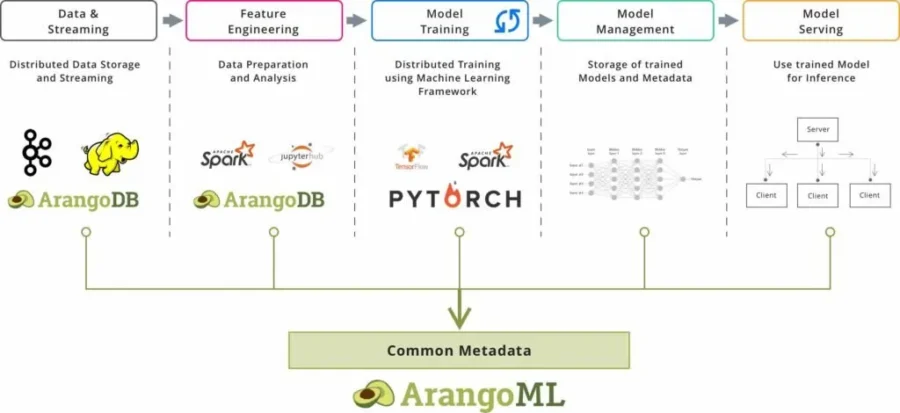
Most of these components have associated metadata including versioned datasets, versioned jupyter notebooks, training parameters, test/training accuracy of a trained model, versioned features, and statistics from model serving.
ML Pipeline Metadata
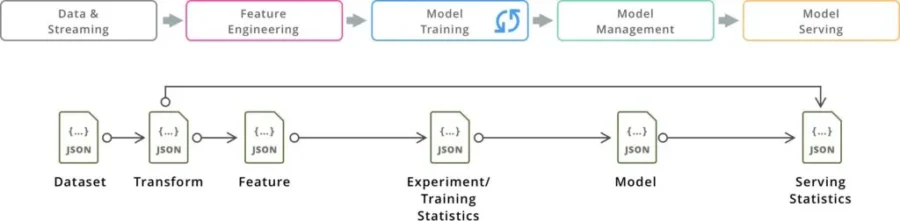
DataOps teams managing these pipelines need a common view across all this metadata and, for instance, want to answer questions about Jupyter Notebooks used for a model currently running in production, or which models running in production have to be updated when new data is available.
A Common Metadata Layer
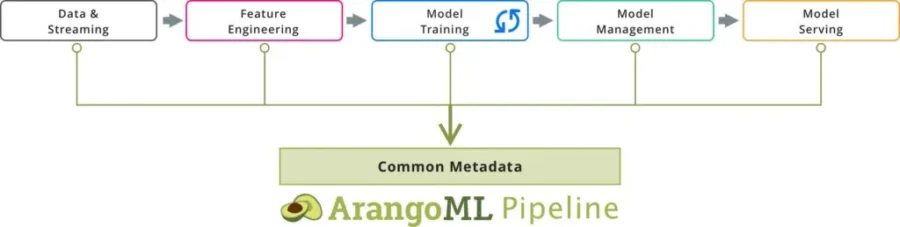
We see many benefits of ArangoML Pipeline for DataOps and Data Scientists:
- Capture of Lineage Information (e.g., Which dataset influences which Model?)
- Capture of Audit Information (e.g, A given model was trained two months ago with the following training/validation performance)
- Reproducible Model Training
- Model Serving Policy (e.g., Which model should be deployed in production based on training statistics)
- Extension of existing ML pipelines through simple python/HTTP API
We highly appreciate your feedback about ArangoML Pipeline on GitHub or join us directly on Slack: Channel #ArangoML.
Want to know more? On Tuesday, October 8, 2019, we will host a webinar with one of the ArangoML Pipeline creators & Head of Machine Learning at ArangoDB Jörg Schad. You can find all the webinar details and register here.
ArangoML Core – Multi-Model Powered Machine Learning
ArangoDB allows for mapping data natively into the database and provides native access via a single query language to perform joins, fulltext search & ranking but also a large variety of graph algorithms.
Having a common query language makes it much simpler for you as a Data Scientists to access different data models, and may also facilitate teamwork with colleagues from DataOps by speaking the same “language”.
The graph capabilities of ArangoDB especially bring great value to machine learning and AI projects as they provide context for Knowledge Graphs, Recommendation Engines and deep learning.
These native multi-model capabilities are quite useful when it comes to feature engineering because they let you easily combine various data aspects into features to be used by Tensorflow or PyTorch to train models.
Simpler Pipeline & Enhanced Feature Engineering

When it comes to ML and especially deep learning, data quantity often plays a crucial role.
ArangoDB is a distributed database and also efficiently processes datasets which are too large for one machine. Features like SmartGraphs or SmartJoins enable the processing of graph and relational queries efficiently even when data is sharded to a cluster.
Furthermore, ArangoDB has native support for a large number of graph algorithms, including PageRank, Vertex Centrality, Vertex Closeness, Connected Components, or Community Detection.
All this might be the reason many teams are already leveraging multi-model today for various ML use cases.
For instance, Innoplexus was able to replace MongoDB, Elasticsearch, Neo4j, and Redis with ArangoDB to serve their document, graph and NLP needs.
The team at Kode Solutions showcase how to use multi-model for semantic tweet analytics via graph combined with semantic search and also developed an ArangoDB package for Rlang.
Large network providers use the combination of JSON and a broad range of graph algorithms in ArangoDB to analyze attack patterns within their network infrastructure and build self-defending network systems.
Knowledge Graph initiatives are a common use case for graph and multi-model. Find a detailed, interactive demo on how to build an adaptive knowledge graph with ArangoDB.
Python users can stay in their favorite language using one of the drivers by either Tariq or Joowani.
To learn more about Multi-Model-Powered Machine Learning please check out our demo using NLP and graph processing for feature engineering here.
Get the latest tutorials, blog posts and news: