
How ArangGraphML Leverages Intel’s PyG Optimizations
Estimated reading time: 3 minutes
ArangoGraphML + Intel: Next-level Machine Learning Accelerated
ArangoDB and Intel have announced a groundbreaking partnership to enhance Graph Machine Learning (GraphML) using Intel’s high-performance processors. This collaboration, part of the Intel Disruptor Program, will seek to integrate ArangoDB’s graph database solutions with Intel’s Xeon CPU. This synergy promises to revolutionize data analytics and pattern recognition in complex graph structures, marking a new era in database technology and GraphML advancements.
ArangoGraphML
ArangoGraphML, part of ArangoDB’s suite, is an advanced graph machine learning platform designed for efficient data analysis and pattern recognition in complex graph structures, leveraging graph database technology to drive innovation in data intelligence and analytics.
Machine Learning Performance Challenge
The quest for speed in machine learning platforms is unending. By delving into Intel’s PyG optimizations, we aim to harness the power of CPU performance enhancements specifically tailored for Graph Neural Network and PyG workloads. As ArangoGraphML is leveraging PyG, any performance improvement is relevant for us and our customers. This exploration is not only about benchmarking Intel’s PyG optimizations but also about internal testing to measure their impact on our platform.
PyG benchmark
Our focus lies on gauging the performance of GraphML algorithms within our platform using torch.compile. This method allows us to assess the efficiency gains brought about by Intel’s PyG optimizations during the training and inference time, providing insights into the tangible benefits for our users.
Benchmark methodology
To ensure a robust evaluation, we conducted tests under controlled conditions:
- System Specifications: We have used an AWS EC2 instance specifically t2.2xlarge with 8 vCPUs and 32 GiB RAM.
- Dataset: We have used ogb-products dataset which is a large-scale undirected and unweighted graph, representing an Amazon product co-purchasing network. The task is to predict the category of a product in a multi-class classification setup, where the 47 top-level categories are used for target labels. This dataset highlights its relevance to real-world scenarios.
- Batch Size, Hidden Layers, and Number of Layers: We have experimented with different essential hyper-parameters in evaluating the performance of GraphML algorithms.
The outcomes
In our preliminary assessments, we observed a noteworthy increase in performance, achieving a speedup of up to 20%. The gains were evident when comparing the execution times of GraphML algorithms with and without Intel’s PyG optimizations. The results are presented graphically in the chart below and summarized in the accompanying table.
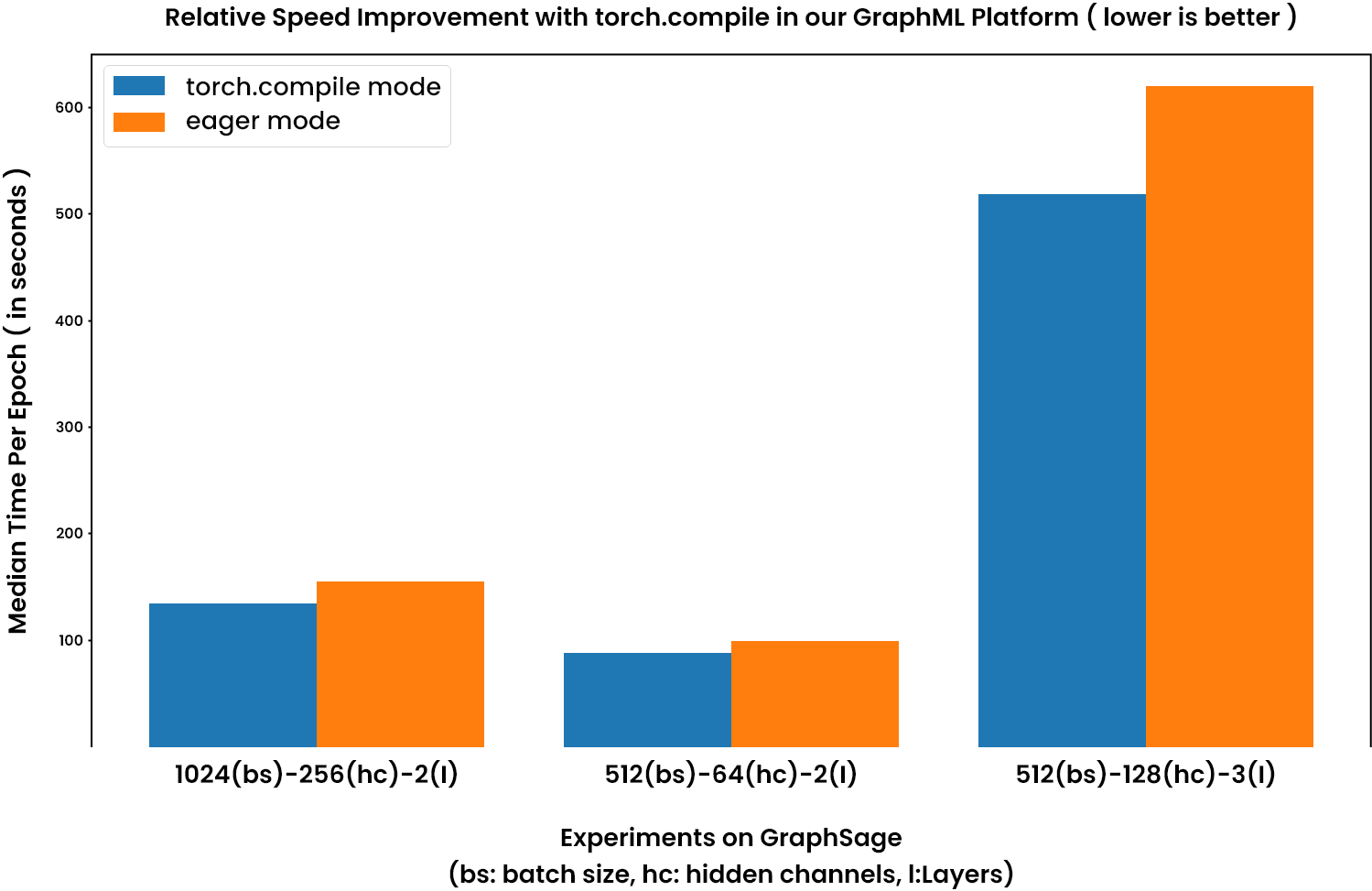
| Batch Size | Hidden Channels | Layers | Mode | Median Time per Epoch (in seconds) | Speed up |
|---|---|---|---|---|---|
| 1024 | 256 | 2 | Eager | 153.803 | |
| 1024 | 256 | 2 | Compile | 134.106 | |
| 1.15x | |||||
| 512 | 64 | 2 | Eager | 89.039 | |
| 512 | 64 | 2 | Compile | 98.714 | |
| 1.11x | |||||
| 512 | 128 | 3 | Eager | ||
| 512 | 128 | 3 | Compile | ||
| 1.12x |
Conclusion
With a demonstrated performance boost, we are now leveraging Intel’s PyG optimizations across our platform. This commitment aligns with our dedication to providing users with cutting-edge technology and optimized algorithms for their Graph Neural Network workflows.
As the field of machine learning continues to evolve, ArangoGraphML remains at the forefront, leveraging Intel’s PyTorch Geometric optimizations to ensure our users experience the fastest and most efficient ML platform available.
Stay tuned for further updates on our journey toward excellence in Graph Machine Learning!
Get the latest tutorials, blog posts and news: