 Skip to content
Skip to content 
Who’s Who in Data Science
Estimated reading time: 10 minutes
Multiple data science personas participate in the daily operations of data logistics and intelligent business applications. Management and employees need to understand the big picture of data science to maximize collaboration efforts for these operations. This article will highlight the specialized roles and skillsets needed for the different data science tasks and the best tools to empower data-driven teams. You will come away from this article with a better understanding of how to support your own data science teams, and it is valuable for both managers and team members alike.
This article will cover some of the different data science personas that exist primarily within the engineering space, aiming to answer the questions:
- What are the different views of Enterprise data?
- What are the different data science personas?
- What is each persona’s relationship to the data?
- What tools do they use?
- What challenges do they face both independently and collaboratively?
We will first need to understand how data is transformed for valuable data science applications and its lifecycle within an enterprise. We will quickly cover some terms that can have different meanings depending on who you are talking to about them. When talking about ‘buzzy’ terms like Enterprise, Big, Operational, and Analytic Data, we must make sure we are talking about the same thing. As these are ever-evolving things, it is equally important to clarify what we perceive these terms to mean, introducing the personas along the way.
There is a lot of information to absorb in this article. So we decided to wrap up with an easily digestible infographic that summarizes the personas we cover here. We won’t blame you for skipping to the bottom if you want the downloadable TLDR.
Enterprise Data
We will follow Fred trying to get a new loan application processed throughout the article. The loan processing includes multiple steps within the enterprise, including the operational and analytic data stores.
Data can have a complex life cycle involving multiple teams and data science personas in a large-scale enterprise environment. The life cycle involves aggregating data from various business (operational) processes, cleaning, and transforming it. The data will be in a form suitable for analysis and performing required analytical tasks to develop data science-driven business applications.
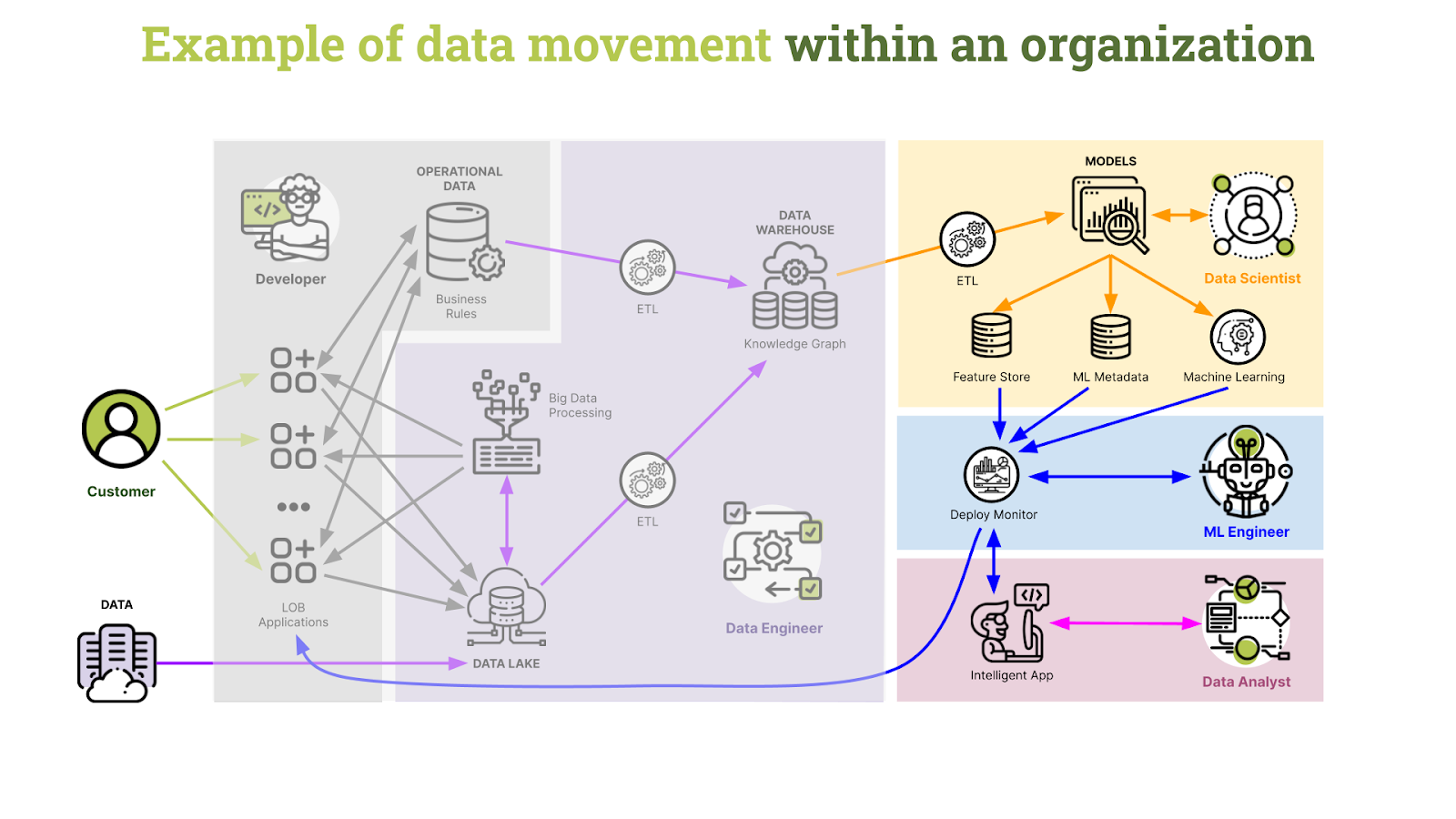
The following diagram shows how data is moved around or accessed within an organization. Data could be potentially stored in any or all of the following:
- Analytical Data Warehouse
- Operational Data Store
- External Data Partners/Platforms
Data will move across different sectors of the enterprise for various tasks relating to:
- Transformation and storage based on business rules
- ETL tasks for loading and modeling data across departments
- Feature engineering and machine learning
- Analytic tasks for technical and non-technical resources
- Production and monitoring

Challenges of Big Data
Big data workloads in the enterprise occur in both operational and analytic environments. Operational workloads capture data from day-to-day business operations. This data is cleaned and later moved to an analytic data warehouse to develop analytic applications.
Understanding the specifics of Enterprise and Big Data is important because understanding the challenges of scaling data is key to understanding the personas that solve these challenges and then utilize the data from there.
See the ISO specification for a formal definition of Big Data. In less specification-laden terms, you are working with big data when you must scale beyond the limits of vertical scalability, possibly scaling horizontally as a result of:
- The amount of data being stored and analyzed is increasing. (volume)
- The processing speed of this data detrimentally decreases. (velocity)
- The stored data contains multiple model types and complicates processing, requiring more compute resources. (variety)
- The combination of the previous three points, the inability to keep up with the dynamic nature of the data coming into the system, and the specific needs for accessing the data frequently change. (variability)
Data Analyst
Primarily concerned with analyzing and presenting data to enable the business to make decisions. They are interested in evaluating business hypotheses to enhance a product feature or understand and assess business conditions. They evaluate a business hypothesis and prepare reports that capture KPIs of business performance.
Data analysts require friction-free data access and an advanced understanding of the database query language. Since the data analysts’ primary focus is business intelligence, they mainly work with reporting tools and limited data science libraries. They are the primary resource to present data to the more non-technical contacts of the business. Thus, they need to access the data required consistently and flexibly to deliver the best view of information to their contacts.
Next up, we dig a little deeper into operational and analytic data.
Operational Data
Operational Big Data systems provide operational capabilities to run real-time, interactive workloads that ingest and store data. These stores offer a unified access point for business applications. Having data housed in these big data stores results in a single source of precious data. Rather than needing to make multiple trips across multiple different data stores, the application can retrieve all necessary information at once.

For the operational data store to maintain its value, it must also be able to scale effectively. One approach for scaling is also what keeps operational data stores so valuable. The operational data store is also behind a business rules application that ensures that only the most valued data is stored in this operational data store. Typically, the raw uncleaned data is kept in a data warehouse to be used later, likely with analytical applications that might need unknown data.
In our loan application scenario, the operational data store integrates data services for multiple parts of the loan application process. There may be a credit score application, risk analysis, general bookkeeping, and property value assessment applications that all eventually store or pull data from the operational data store.
Data Engineers
Data engineers are primarily concerned with engineering the data pipelines and the infrastructure needed to support the needs of the other three participants in this table. They collaborate extensively with the other participants and understand the needs motivating the data requirements of the other participants.
Data engineers need to perform experiments to evaluate if a pipeline fulfills the needs of the consumers. They require proficiency with data querying as well as data integration tools. The data engineer will spend a lot of their time doing tasks such as data wrangling and are in charge of systems controlling data governance and archival.
Data Processing
A large portion of data science work involves dealing with the data from our daily big data operations. Big data platforms are in charge of collecting digital exhaust, interaction analytics, logs, and non-business data. These systems typically handle tasks such as clickstreams and interface with systems such as Hadoop and Spark, which feed into other systems, including Impala and Hive. These systems are the primary domain for a data engineer.
There needs to be an ETL layer within these systems that ensures that the data is prepared for the eventual machine learning or analytics work.

Our diagram shows that the data storage and processing systems bridge our operational data store and the ML and analytics processes. This diagram further highlights the importance of the data engineer and how vital it is that they can effectively collaborate with the other participants.
Analytic Data
Suppose we continue with the loan application example from the operational data store section. In that case, analytic data involves the process of aggregating data from multiple parts of the operational applications and eventually running, typically read-only, queries to infer new information. So the analytical side would be more interested in the default rate for loans granted over five years and the associated credit scores to determine if the business should update the loan approval process.
Typically, operational data stores operate in an environment where they respond to events and persist data. They are more involved in the day-to-day operations of the application, while the analytic data stores are involved in the analysis of the days’, months’, or years’ work.
Processing the business data for analytical purposes could involve removing personally identifiable information and performing other regulatory checks, for example, verifying that all required information has been consolidated. (in a loan, this could be things like late charges). Once this is done, the data is suitable for analysis to support business decisions, for example:
1. Understanding customer aggregate behavior, ex: grouping customers into good credit, lower risk, and customers who have defaulted.
2. Developing cross-selling applications, ex: target customers with good credit ratings for opportunities to apply for new loans.
3. Identification of a set of activities that are possibly suspicious or require further investigation.
Data Scientist
A data scientist is primarily concerned with experimentation and hypothesis evaluation on business data. These activities support the improvement of existing business applications or motivate the development of new ones. They answer the question: “What is the best way to solve this problem with a model?” Once they have answered that question, they are in charge of creating and defining the real-world solution.
A data scientist needs to be able to obtain the data necessary to evaluate their hypotheses. This process is directly tied to the work of the data engineers. They must also be able to document their findings for reproducibility and monitoring, should the model be moved to production. The capturing of machine learning pipeline metadata and model productionizing is the responsibility of the machine learning engineer.
While a data scientist may be a database query guru, they need a database with a robust and easy to query language to facilitate getting the necessary data for their external data science libraries. The bulk of their query work will be light analytics and data exploration of the data stored in the database.
They will primarily work with data science libraries and utilities such as NetworkX, PyTorch, Tensorflow, and visualization libraries. The data scientist wil be in charge of figuring out the algorithm to use to solve the problem they are working on but this solution usually needs a bit of refining and this is where the Machine Learning Engineer comes in.
Machine Learning Engineer
Finally, the machine learning pipelines are tightly coupled with the analytics systems and require someone to manage this relationship; this is the job of the machine learning engineer. A machine learning engineer optimizes and refines established data science models. They are primarily concerned with productionizing an optimized machine learning model. As shown in our diagram, the model generation performed by the data scientists is what the ML engineer will deploy, monitor, and productionize. They will follow up with the data analyst for quality assurance and ensure friction-free access to the resulting data. They will also communicate model performance metrics back to the data scientist.
The ML engineer will need expertise in both the field of operations and machine learning to deploy the most optimal models; finding these optimizations is usually the result of experimentation. The ML Engineer usually works with model information provided by the data scientist and attempts to clean it up and make it as efficient and production-ready as possible.
Data Science Personas Infographic
This infographic summarizes the data included in this article. It briefly describes the role of each persona, what they need to achieve their day-to-day tasks and the tools and features they use or desire.
(Click to open larger size)

Conclusion
This article covered four of the different data science personas that make up many data science teams. You should now understand more about these personas, the different views of Enterprise data, and each persona’s relationship to the data.
Hopefully, this article will empower you to either understand your own role within your team better or to better understand how to better support your data science teams.
Hear More from the Author
ArangoBnB: Data Preparation Case Study
Continue Reading
Integrate ArangoDB with PyTorch Geometric to Build Recommendation Systems
Get the latest tutorials, blog posts and news: